[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
Kafka Streams vs. Spark Streaming: Key Differences
Kafka Streams is a client library for stream processing built on top of Apache Kafka®. It enables the development of real-time applications that can process and analyze streams of data directly within Kafka. Unlike traditional stream processing systems, Kafka Streams operates in the Kafka ecosystem itself, making it an ideal choice for users already leveraging Kafka for event streaming.
Spark Streaming, on the other hand, is an extension of Apache Spark™ that provides stream processing capabilities as a modification to Spark’s batch-processing protocol. Rather than continuously processing data, it works by breaking incoming data into small, fixed-size batches, thus enabling stream processing within Spark’s existing distributed computing framework. While Kafka Streams is integrated with Kafka for seamless stream processing, Spark Streaming is a more general-purpose framework that can handle stream processing for various data sources.
Both Kafka Streams and Spark Streaming are popular choices for stream processing use cases, but the choice between the two generally depends on specific requirements such as scalability, latency, and integration with existing data systems. To determine which technology is best suited for your specific use cases, you need to understand the architectural distinctions between the two.
What Is Apache Spark?
Apache Spark is a fast, in-memory distributed computing framework designed for large-scale data processing. Initially designed for batch processing, Spark excels at processing large volumes of data in parallel, leveraging its distributed architecture. Batch processing involves executing a series of operations over a fixed-size dataset, typically at regular intervals, and is suitable for workloads where real-time processing is not a requirement.
Stream Processing vs. Batch Processing
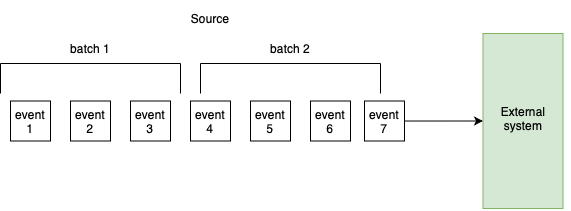
While batch processing involves processing data in chunks or large blocks, stream processing refers to processing data continuously as it arrives in real-time. Batch processing is often more efficient for large-scale, static datasets that do not require immediate action or low-latency processing. However, stream processing is crucial for use cases that demand real-time insights or immediate data transformation.
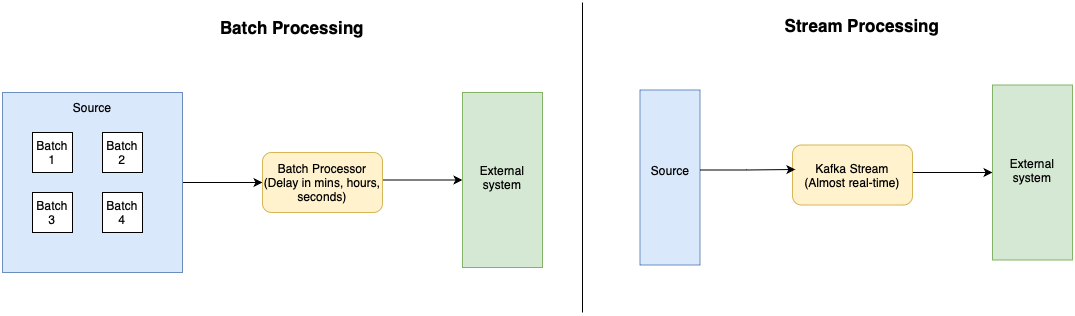
A comparison of batch vs. stream processing
Spark Streaming was introduced as a solution to the challenges of real-time data processing. It works on the concept of batch processing by dividing incoming data into micro-batches and then processing these batches using Spark’s computational framework. This hybrid approach—called micro-batching—strikes a balance between the flexibility of stream processing and the efficiency of batch processing.
In contrast, Kafka Streams takes an approach to stream processing that the data is taken from the source systems directly without converting them into batches. The processing on such systems is done in real time.
History and Purpose of Spark Streaming
Spark Streaming was developed to overcome the limitations of traditional batch processing in Spark. Before Spark Streaming, users could not easily perform continuous data analytics using Spark's batch-oriented model. Spark Streaming was created to fill this gap and allow stream-style data processing, which was becoming increasingly important for use cases like fraud detection, security information and event management, and real-time analytics.
Spark Streaming vs. Apache Kafka: Micro-Batching vs. Real-Time Streaming
While Spark Streaming uses a micro-batch architecture, Apache Kafka offers true real-time data streaming. This distinction is crucial: in micro-batch processing, data is processed in small, fixed-size batches, whereas real-time streaming involves the continuous, unbounded processing of data as it flows.
Key Differences Between Data Streaming and Micro-Batch Processing:
|
Attribute |
Data Streaming |
Micro-Batch |
|
Latency |
Low latency, processed as data arrives |
Higher latency due to batch intervals |
|
Processing Model |
Continuous stream processing |
Batch-based processing at fixed intervals |
|
Use Case Suitability |
Real-time analytics, event-driven systems |
Periodic analytics, fault-tolerant systems |
When to Use Kafka Streams vs. Spark Streaming
Kafka Streams is an ideal choice when you need to process and analyze streams of data directly within the Kafka ecosystem. It is lightweight, easy to deploy, and well-suited for event-driven microservices or real-time analytics. Kafka Streams provides powerful abstractions for processing streams, including time-based windows, aggregation, and stateful processing.
Kafka Streams is designed to operate directly with Kafka topics, making it a natural fit for users already leveraging Kafka as a messaging backbone. For example, Kafka Streams can be used to process real-time data from IoT devices, aggregate logs for monitoring, or perform dynamic anomaly detection.
If you start with Kafka Streams for simpler, Kafka-native transformations and then realize you need the more advanced capabilities of Apache Flink® for more complex pipelines, the transition or coexistence is natural. Kafka acts as the central nervous system, and both Kafka Streams and Flink can read and write to Kafka topics. You can even use Kafka Streams for initial data cleaning and enrichment and then feed those refined topics into Flink for deeper analysis.
Spark Streaming, on the other hand, is a good option for organizations already using Apache Spark and those that require more complex analytics or need to integrate data from various sources. Spark Streaming supports integration with a variety of data systems beyond Kafka, such as HDFS, S3, and relational databases. It is particularly well-suited for data-intensive applications that require distributed processing over large volumes of data.
While Kafka Streams is great for scenarios focused on Kafka, Spark Streaming is better suited for more diverse, high-volume, multi-source stream processing applications. Spark Streaming is also more appropriate for those who need advanced machine learning capabilities or integration with Spark’s data processing framework.
Example Use Cases & Code Snippets for Kafka Streams
Common Use Cases
-
Event-Driven Microservices: Both Kafka Streams and Spark Streaming are used in building event-driven systems where microservices interact in real time. Kafka Streams, with its tight integration with Kafka, is well-suited for lightweight, highly scalable event processing, while Spark Streaming can handle more complex analytics on the event stream.
-
Real-Time Analytics: Kafka Streams is a strong choice for simple real-time analytics, such as real-time dashboards or monitoring applications. Spark Streaming, on the other hand, is better for performing heavy computations on the stream, such as machine learning models or aggregating large datasets.
-
Log Aggregation: Kafka Streams can handle real-time log processing with low latency, while Spark Streaming can be used when log data needs to be processed at scale, possibly from various sources, and then analyzed or stored in databases.
Here’s a simple example of Kafka Streams code that counts the number of occurrences of words in a stream of text:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("input-topic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(value ->
Arrays.asList(value.toLowerCase().split(" ")))
.groupBy((key, value) -> value)
.count(Materialized.as("word-counts-store"));
wordCounts.toStream().to("output-topic",
Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
This example processes data from an input-topic, splits the text into words, counts the occurrences, and writes the result to an output-topic.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="NetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
wordCounts = words.countByValue()
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
This Python snippet reads text data from a socket stream, splits it into words, counts the occurrences, and prints the results.
For more in-depth use case content, refer to the Confluent use case library.
Next Steps for Learning Stream Processing
Both batch processing and stream processing have important roles in modern data pipelines. When leveraging Kafka as the backbone of your architecture, you gain the flexibility to integrate a wide variety of stream processing technologies such as Kafka Streams, Flink, and Spark Streaming. This allows users to mix and match the best tool for their needs, whether it's Kafka Streams for low-latency, Kafka-integrated processing with Flink, or Spark Streaming for distributed, high-volume data processing.
For more insights into building robust stream processing systems using Kafka, explore this guide on stream processing.
Ready to dive deeper? Start your journey with Kafka Streams and Spark Streaming today—sign up for a free trial of Confluent Cloud and join our webinars or workshops to learn more about the real-world use cases covered in this article.