[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
What is Kafka Retention? Policies, Configuration, and Best Practices
In Apache Kafka®, retention is the policy that controls how long Kafka keeps messages in a topic before deleting them or compacting them to save space and manage data efficiently. Retention is essential for managing storage efficiently and ensuring that Kafka clusters operate predictably over time. Without a clear Kafka message retention strategy, disk usage can grow uncontrollably, leading to performance degradation or node failure.
Why Apache Kafka® Retention Matters
Apache Kafka is a distributed streaming platform designed for high-throughput, fault-tolerant event processing. That’s what makes Kafka retention such a fundamental concept for developers to understand and apply—how long you choose to store messages in a topic before deleting or compacting them directly impacts the data availability and system health of applications you build with Kafka.
Once the configured Kafka retention period is exceeded, older messages are either deleted or compacted depending on the Kafka retention policy in place. As such, having a well-defined Kafka data retention strategy is critical for:
-
Ensuring durability for downstream consumers that may read at different speeds
-
Controlling storage costs in on-premises or cloud-based deployments
-
Supporting compliance requirements, like retaining financial logs for a fixed number of days
-
Preventing backlogs and operational bottlenecks
Kafka’s retention behavior is topic-specific and can be fine-tuned at the topic level or cluster-wide using configuration settings.
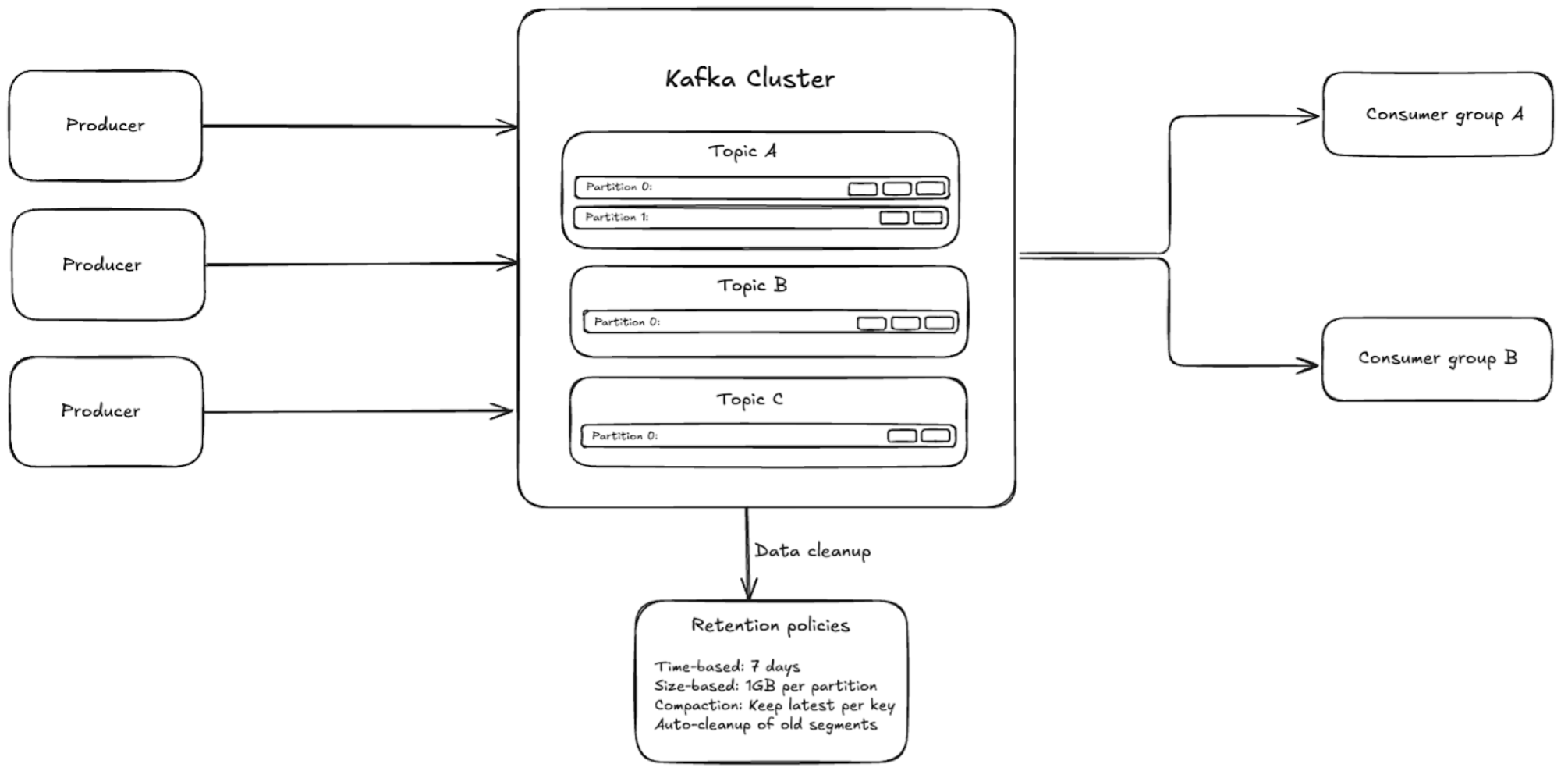
Kafka Retention Policy
Kafka provides robust retention features that allow developers to manage data lifecycles effectively. By configuring Kafka retention policies, you can control how long messages remain in a topic and when they are either deleted or compacted. This capability is crucial for balancing storage costs and ensuring data availability for consumers.
Kafka supports two primary retention policies:
-
Time-based Retention: Messages are retained based on a specified time duration.
-
Size-based Retention: Messages are retained based on the total size of data stored in a topic.
Configuring Kafka Retention Policies
Kafka's default retention settings are defined in the server.properties file. Key configurations include:
-
log.retention.hours – Specifies the duration (in hours) that messages are retained. Default: 168 hours (7 days)
-
log.retention.bytes – Specifies the maximum size (in bytes) that a topic log segment can reach before older messages are deleted. Default: -1 (no limit)
-
log.retention.check.interval.ms – Frequency at which Kafka checks for logs to delete or compact. Default: 300,000 ms (5 minutes)
To update these settings, you can modify the configurations at the topic level using the CLI:
kafka-configs.sh --alter --entity-type topics --entity-name <topic-name> --add-config
retention.ms=259200000
This command sets the retention period to 3 days (259200000 ms) for a specific topic.
Types of Kafka Retention Policies
-
Time-based Retention:
-
Retains messages for a specific duration.
-
Configured using retention.ms or log.retention.hours.
-
Example: Setting retention.ms=86400000 will retain messages for 1 day.
-
-
Size-based Retention:
-
Retains messages until the log reaches a specific size.
-
Configured using log.retention.bytes.
-
Example: Setting log.retention.bytes=104857600 will retain up to 100 MB of data in the topic.
-
How messages in Kafka are retained no retention policy in place, a time-based policy, or a size-based policy
Kafka Retention Use Cases
Understanding when and how to implement different Kafka retention policies becomes clearer when examined through real-world use cases. The following scenarios demonstrate how proper retention configuration supports various architectural patterns and business requirements.
Data Archiving for Compliance and Auditing
Financial services, healthcare, and other regulated industries often require data retention periods spanning months or years to meet compliance requirements. In these scenarios, Kafka message retention serves as the first line of defense for audit trails and regulatory reporting.
Consider a payment processing system where transaction events must be retained for seven years to comply with financial regulations:
# Configure long-term retention for audit trail topic
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name payment-audit-trail \
--alter \
--add-config retention.ms=220898400000 # 7 years in milliseconds
For compliance use cases, configure retention policies with generous time limits while implementing log compaction for key-based deduplication. This approach maintains regulatory compliance while managing storage costs effectively.
Key considerations for data archiving:
-
Set retention periods that exceed regulatory requirements by a comfortable margin
-
Implement proper data encryption and access controls
-
Consider using tiered storage solutions for cost optimization
-
Monitor disk usage patterns to prevent storage exhaustion
Event Sourcing and Event-Driven Architectures
Event sourcing relies on Kafka's ability to preserve the complete history of domain events, enabling system reconstruction from any point in time. Kafka retention policies directly impact the replayability window for event-driven applications.
In event sourcing scenarios, retention configuration depends on your recovery and replay requirements:
# Configure retention for event store topic
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name user-events \
--alter \
--add-config retention.ms=2592000000,cleanup.policy=compact
Event sourcing applications benefit from log compaction combined with extended retention periods. This configuration preserves the latest state for each entity key while maintaining historical events for replay scenarios.
Best practices for event sourcing retention:
-
Use compacted topics for aggregate state preservation
-
Implement snapshot mechanisms to reduce replay time
-
Configure retention periods based on business continuity requirements
-
Consider separate topics for different event types with varying retention needs
Data Aggregation and Historical Analytics
Analytics pipelines frequently require access to historical data for trend analysis, machine learning model training, and business intelligence reporting. Kafka data retention policies determine the available time window for these analytical workloads.
Time-series data aggregation represents a common pattern where raw events are processed into hourly, daily, and monthly summaries:
# Raw events with shorter retention
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name raw-metrics \
--alter \
--add-config retention.ms=604800000 # 7 days
# Aggregated data with longer retention
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name daily-aggregates \
--alter \
--add-config retention.ms=7776000000 # 90 days
This tiered approach optimizes storage costs while preserving different granularities of data for various analytical needs. Raw data supports real-time processing, while aggregated data enables long-term trend analysis.
Analytics retention strategies:
-
Implement data tiering with different retention periods for different aggregation levels
-
Use size-based retention for high-volume topics to prevent storage issues
-
Consider external data lakes for long-term historical storage
-
Monitor consumer lag to ensure analytical jobs complete within retention windows
Stream Processing and Windowed Operations
Stream processing applications performing windowed operations require sufficient Kafka message retention to support late-arriving data and application restarts. The retention period must accommodate both your processing window and recovery scenarios.
For applications processing hourly windows with potential late arrivals:
# Configure retention to support windowed processing
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name clickstream-events \
--alter \
--add-config retention.ms=259200000 # 3 days for late arrivals and recovery
Stream processing retention considerations:
-
Set retention periods longer than your maximum processing window
-
Account for application downtime and recovery scenarios
-
Balance storage costs against data completeness requirements
-
Implement proper watermarking strategies for late data handling
How to Configure Kafka Retention
Proper Kafka retention configuration requires understanding the hierarchy of settings and how to apply policies at different levels. Kafka provides flexible retention mechanisms through time-based and size-based policies that can be configured globally or per topic.
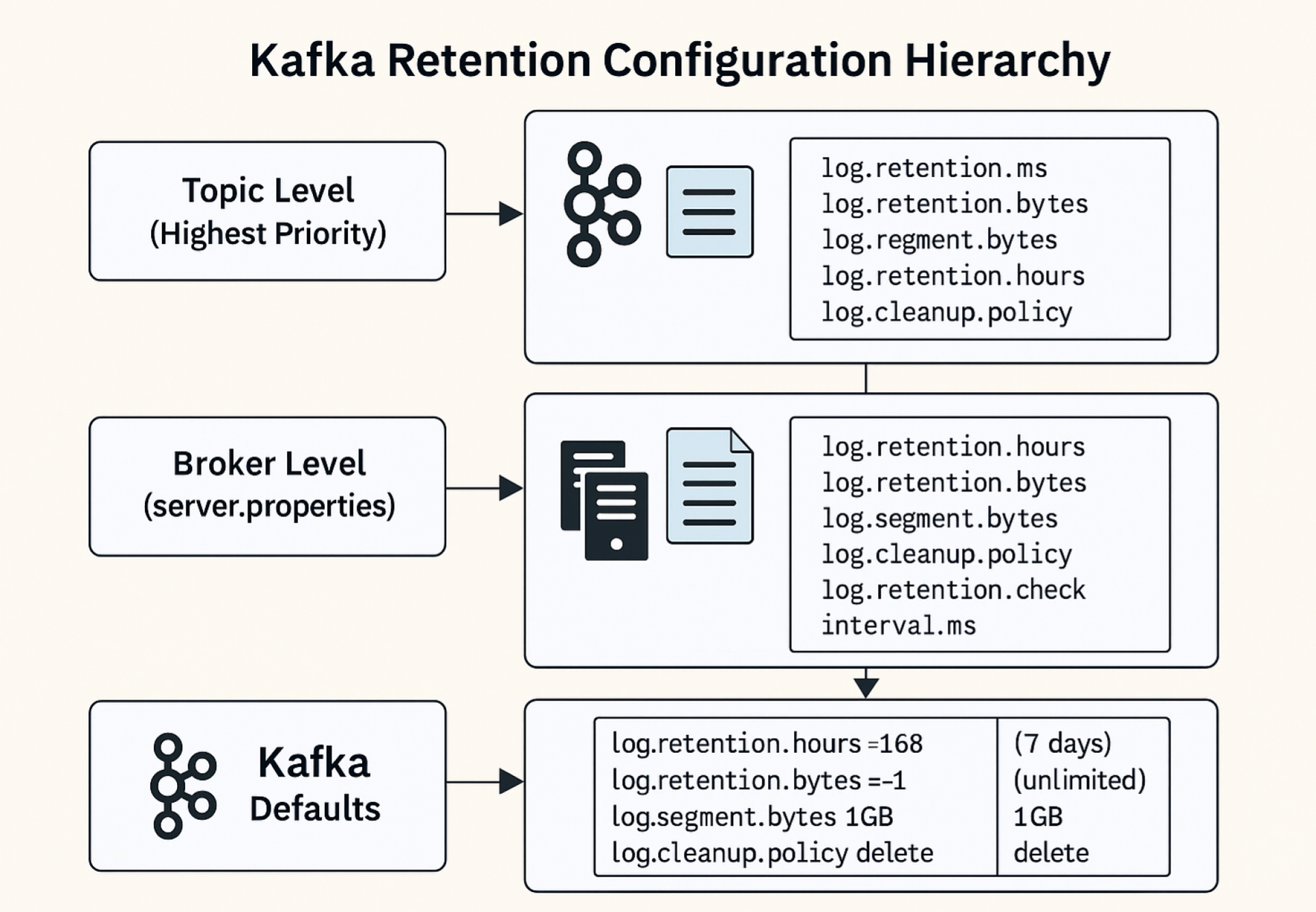
Understanding Kafka Retention Configuration Hierarchy
Kafka retention policies follow a specific precedence order: topic-level configurations override broker-level defaults. This hierarchy allows you to set reasonable defaults cluster-wide while customizing retention for specific use cases.
The configuration precedence works as follows:
-
Topic-level configurations (highest priority)
-
Broker-level defaults (fallback when topic settings are not specified)
-
Kafka defaults (applied when no explicit configuration exists)
Time-Based Retention Configuration
Time-based retention controls how long Kafka retains messages based on their timestamp. Multiple time-based parameters provide flexibility in defining retention periods with different granularities.
Key Time-Based Parameters
log.retention.ms - Retention time in milliseconds (highest precision)
# Set retention to 7 days (604,800,000 milliseconds)
log.retention.ms=604800000
log.retention.hours - Retention time in hours (most commonly used)
# Set retention to 168 hours (7 days)
log.retention.hours=168
log.retention.minutes - Retention time in minutes (rarely used)
# Set retention to 10,080 minutes (7 days)
log.retention.minutes=10080
When multiple time-based parameters are specified, Kafka uses the parameter with the smallest unit (milliseconds takes precedence over hours).
Size-Based Retention Configuration
Size-based retention limits help prevent topics from consuming excessive disk space by setting maximum log segment sizes and total log sizes.
Essential Size-Based Parameters
log.retention.bytes - Maximum size for all log segments in a topic partition
# Set maximum log size to 1GB per partition
log.retention.bytes=1073741824
log.segment.bytes - Maximum size for individual log segments
# Set segment size to 100MB
log.segment.bytes=104857600
log.roll.hours - Time after which Kafka creates new log segments
# Create new segments every 24 hours
log.roll.hours=24
Size-based retention works in conjunction with time-based policies. Kafka applies whichever condition is met first, providing dual protection against both time and storage constraints.
Broker-Level Configuration
Broker-level settings establish default retention policies for all topics on the cluster. Configure these parameters in the server.properties file for each Kafka broker.
Sample Broker Configuration
# Time-based retention defaults
log.retention.hours=168 # 7 days default retention
log.retention.check.interval.ms=300000 # Check every 5 minutes
# Size-based retention defaults
log.retention.bytes=-1 # No size limit by default
log.segment.bytes=1073741824 # 1GB segment size
# Log cleanup and compaction
log.cleanup.policy=delete # Default cleanup policy
log.cleaner.enable=true # Enable log cleaner
After modifying broker configurations, restart all brokers in the cluster to apply changes. Rolling restarts minimize service disruption while ensuring configuration consistency.
Topic-Level Configuration
Topic-level configurations provide granular control over retention policies for specific use cases. These settings override broker defaults and can be applied during topic creation or modified on existing topics.
Creating Topics with Custom Retention
# Create topic with 30-day retention and 500MB size limit
kafka-topics.sh --bootstrap-server localhost:9092 \
--create \
--topic user-events \
--partitions 6 \
--replication-factor 3 \
--config retention.ms=2592000000 \
--config retention.bytes=524288000
Modifying Existing Topic Retention
# Update retention policy for existing topic
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name user-events \
--alter \
--add-config retention.ms=1209600000,retention.bytes=1073741824
Using Kafka APIs for Dynamic Configuration
The Kafka Admin API provides programmatic access to retention configuration, enabling dynamic policy adjustments based on application requirements or operational conditions.
Java Admin API Example
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.config.ConfigResource;
// Configure retention via Admin API
Properties adminProps = new Properties();
adminProps.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
try (AdminClient adminClient = AdminClient.create(adminProps)) {
ConfigResource resource = new ConfigResource(
ConfigResource.Type.TOPIC, "user-events");
Map<ConfigResource, Config> configs = Map.of(
resource, new Config(Arrays.asList(
new ConfigEntry("retention.ms", "604800000"),
new ConfigEntry("retention.bytes", "1073741824")
))
);
AlterConfigsResult result = adminClient.alterConfigs(configs);
result.all().get(); // Wait for completion
}
Retention Impact on Storage
The retention strategy you choose affects disk usage. Here’s a simplified table comparing scenarios:
|
Use Case |
Retention Policy |
Estimated Storage Use |
Ideal For |
|
Short-lived telemetry |
retention.ms=6h |
Low (~1 GB/day/topic) |
Stream processing pipelines |
|
Compliance logs |
retention.ms=30d |
High (~50 GB/month) |
Auditing, archiving |
|
Log rotation by size |
retention.bytes=1GB |
Capped at 1 GB |
Disk space constrained setups |
|
Combined |
retention.ms=3d + retention.bytes=5GB |
Up to limit |
Hybrid use cases |
5 Best Practices for Retention Configuration
- Start Conservative: Begin with shorter retention periods and extend based on actual requirements rather than starting with excessive retention that wastes storage.
- Monitor Before Adjusting: Establish baseline metrics for storage usage, consumer lag, and cleanup performance before making configuration changes.
- Test Configuration Changes: Use development or staging environments to validate retention policy changes before applying to production clusters.
- Document Retention Rationale: Maintain clear documentation explaining why specific retention policies were chosen for each topic, including business requirements and compliance considerations.
- Regular Review Cycles: Schedule periodic reviews of retention policies to ensure they still align with evolving business needs and cost optimization goals.
How Kafka Handles Log Cleanup
Efficient log cleanup is essential for managing disk usage and ensuring Kafka remains performant over time. As Kafka retains vast amounts of data, the log cleanup process determines what data gets removed and when, based on the Kafka retention policy applied to each topic.
Why Log Cleanup Matters
Without automatic cleanup, Kafka brokers would run out of disk space, eventually halting ingestion and processing. Log cleanup:
-
Frees up disk by removing expired or excess data
-
Keeps only the relevant, recent, or latest records
-
Ensures high-throughput, low-latency operations at scale
Properly configuring Kafka retention policy allows the system to automatically clean up old data, optimizing storage while preserving relevant messages.
Log Deletion: Retention-Based Cleanup
Kafka deletes log segments that exceed configured retention.ms (time-based) or retention.bytes (size-based) limits.
Process Overview:
-
Each Kafka topic partition is broken into multiple segment files.
-
Kafka periodically checks each segment's creation time and total size.
-
Segments older than retention.ms or exceeding retention.bytes are deleted during the cleanup cycle (default: every 5 minutes).
-
The oldest segment is deleted first to free up space.
Example:
-
If retention.ms is set to 2 days, any segment older than 48 hours is deleted.
-
If retention.bytes is set to 1GB, the oldest segment is deleted once the total log size exceeds 1GB.
Relevant Parameters:
-
retention.ms
-
retention.bytes
-
log.retention.check.interval.ms
Note: Deletion is irreversible. Consumers must read messages before they are purged.
Log Compaction: Retaining the Latest Record per Key
Log compaction is a cleanup strategy focused on retaining the most recent message for each key rather than deleting data based on time or size.
-
Unlike deletion, compaction preserves the most recent record for each key, even if the segment size or age exceeds configured limits.
-
Configured using the cleanup.policy=compact parameter at the topic level.
When to Use:
-
Storing the latest state of an entity (e.g., user profiles, inventory counts)
-
Enabling changelog topics for Kafka Streams
How It Works:
-
Compaction runs in the background on topics with cleanup.policy=compact.
-
Kafka scans segment files for duplicate keys.
-
Only the latest value for each key is retained.
-
Older records for the same key are removed, freeing disk space without losing current state.
Relevant Parameters:
-
cleanup.policy=compact
-
segment.ms, min.cleanable.dirty.ratio
Key Differences: Log Deletion vs. Log Compaction
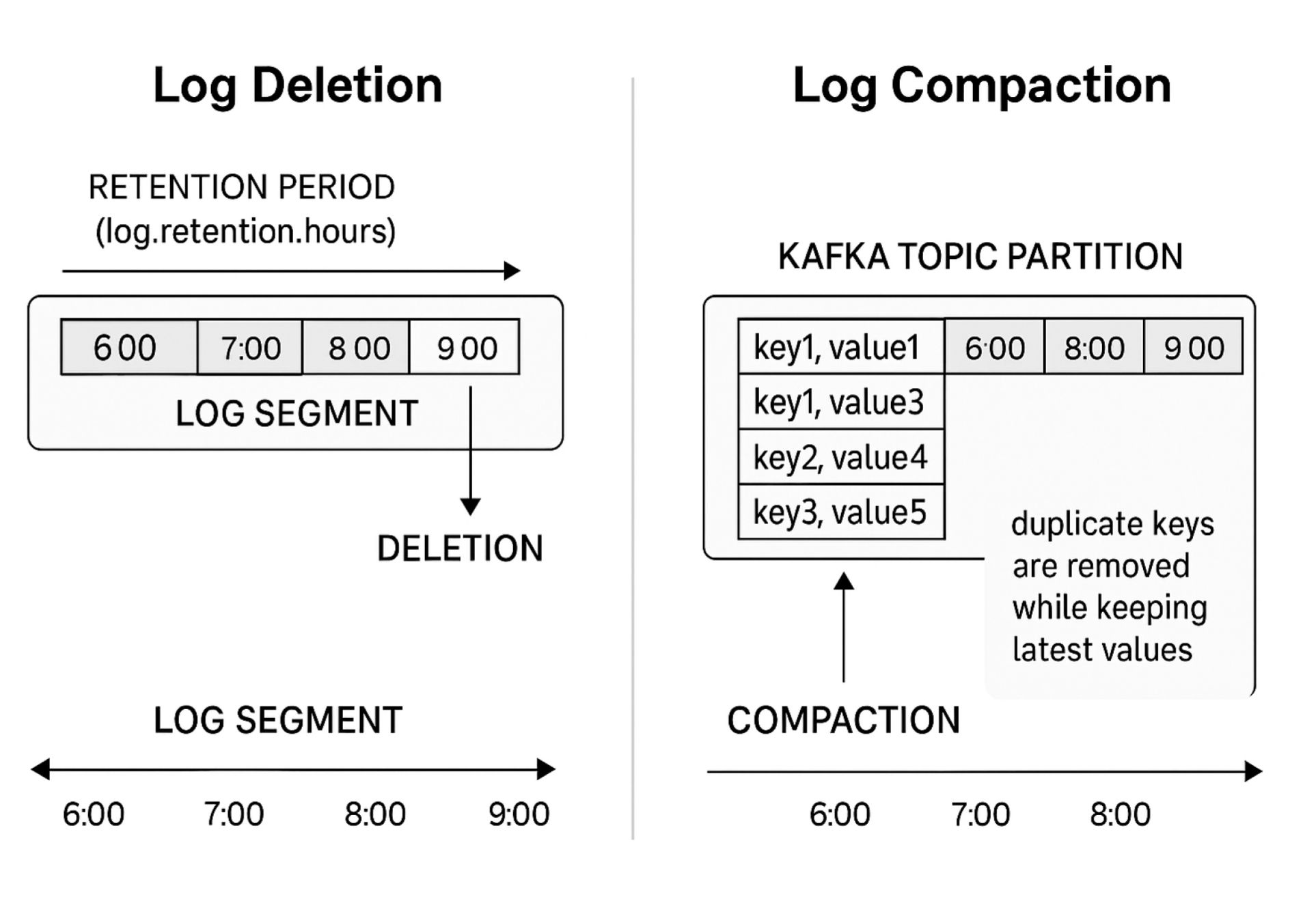
Log Deletion vs. Log Compaction, Visualized
|
Aspect |
Log Deletion |
Log Compaction |
|
Purpose |
Delete old messages |
Retain latest record per key |
|
Trigger |
Time-based or size-based limits |
Key-based record compaction |
|
Data Removal |
Deletes entire segments |
Removes outdated records for each key |
|
Use Case |
Temporary data, streaming logs |
Transactional data, state storage |
|
Configuration |
cleanup.policy=delete |
cleanup.policy=compact |
Table 1. Summary of Differences Between Log Deletion and Log Compaction
Segment Rotation and Retention Flow
Kafka log segments follow a rollover and cleanup pattern based on configured segment size/time:
-
Messages are written to the active segment.
-
Once segment.bytes or segment.ms is reached, Kafka rolls over to a new segment.
-
Older segments are eligible for cleanup via:
-
Deletion (based on retention limits)
-
Compaction (if enabled for the topic)
-
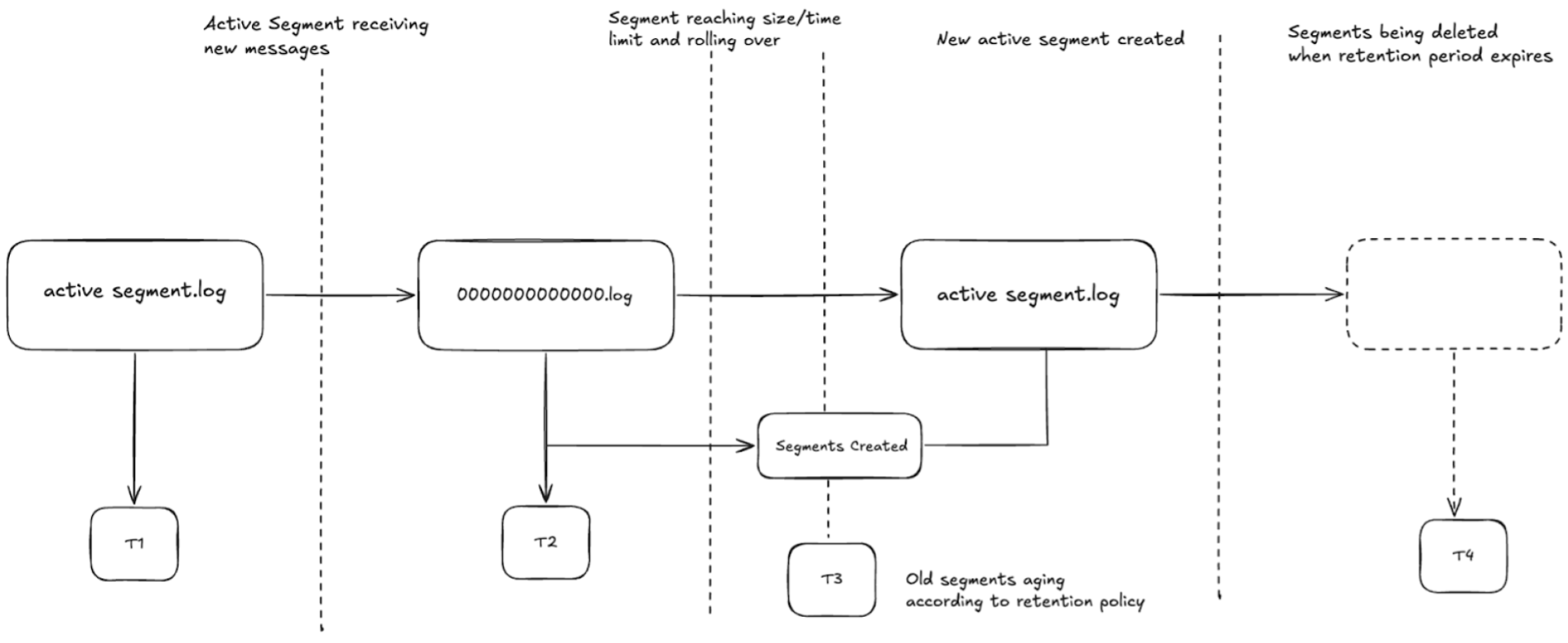
Segment Rotation and Retention Flow Visualized
Troubleshooting Kafka Retention Issues
Even with careful configuration, Kafka retention issues can occur due to misconfigurations, unexpected behavior, or environmental factors. Understanding common problems and their solutions helps maintain stable cluster operations.
Common Retention Problems and Root Causes
Misconfigured Retention Policies
Configuration conflicts represent the most frequent source of retention issues. These problems typically arise from inconsistent settings between broker and topic levels or incorrect parameter values.
Observations:
-
Data retention periods don't match expectations
-
Inconsistent behavior across topics or partitions
-
Error messages during topic creation or configuration updates
Factors:
# Conflicting time-based settings
retention.ms=604800000 # 7 days
retention.hours=720 # 30 days - CONFLICT!
# Invalid size configurations
retention.bytes=0 # Invalid - should be -1 for unlimited
segment.bytes=50000000000 # Exceeds practical limits
Unexpected Data Deletion
Data disappearing sooner than expected often results from multiple retention policies being applied simultaneously or cleanup processes running more aggressively than anticipated.
Log compaction doesn’t delete all old messages—only those with older keys—based on latest value retention. Accidental deletions usually stem from delete policy being active alongside compaction.
Observations:
-
Messages deleted before reaching configured retention time
-
Consumer applications encountering missing data
-
Shorter-than-expected data availability windows
Factors:
-
Size-based retention triggering before time-based limits
-
Log compaction removing messages unintentionally
-
Aggressive segment rolling causing premature cleanup
Excessive Disk Usage
Topics consuming more storage than anticipated can overwhelm broker disk capacity and impact cluster performance.
Observations:
-
Rapidly increasing disk usage despite retention policies
-
Broker performance degradation due to I/O pressure
-
Disk space alerts or broker failures
Factors:
-
Retention policies set too liberally
-
High-volume topics without appropriate size limits
-
Log compaction not running effectively
-
Large message sizes causing segment bloat
Diagnostic Commands and Techniques
Checking Current Retention Configuration
Start troubleshooting by verifying actual topic configurations against expected settings:
# Examine topic-level retention settings
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name problematic-topic \
--describe
# Check broker-level defaults
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type brokers \
--entity-name 0 \
--describe
Analyzing Log Directory Structure
Inspect the physical log structure to understand segment organization and sizes:
# Check log directory contents and sizes
kafka-log-dirs.sh --bootstrap-server localhost:9092 \
--describe \
--json | jq '.brokers[0].logDirs[0].partitions[]'
# Monitor segment files directly on broker filesystem
ls -lah /var/kafka-logs/topic-name-*/
Monitoring Cleanup Activity
Track log cleanup operations to identify performance bottlenecks or failures:
# Monitor log cleaner performance
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--describe --all-groups | grep __consumer_offsets
# Check cleanup thread status in JMX metrics
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic __consumer_offsets --formatter kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter
Resolution Strategies for Common Issues
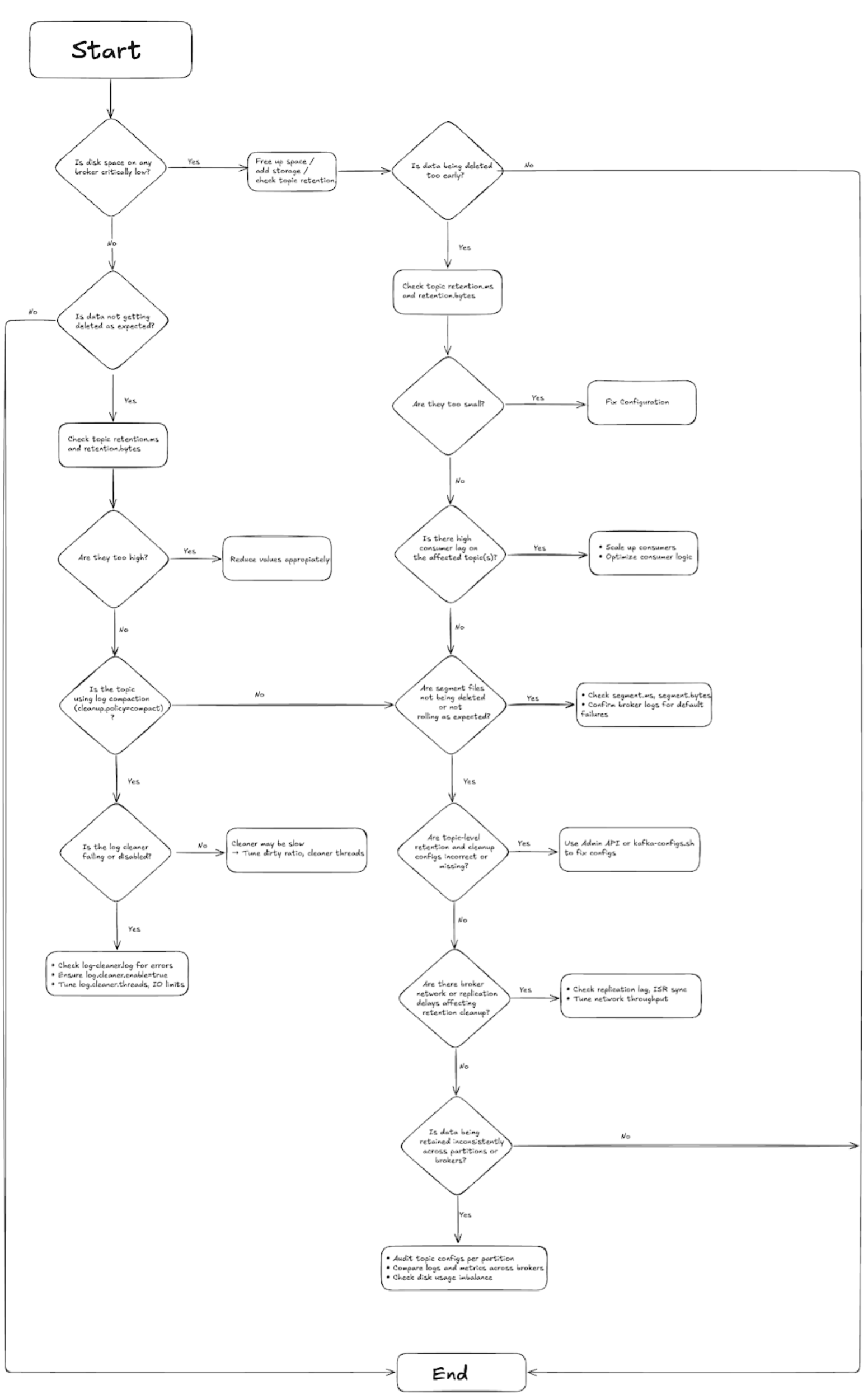
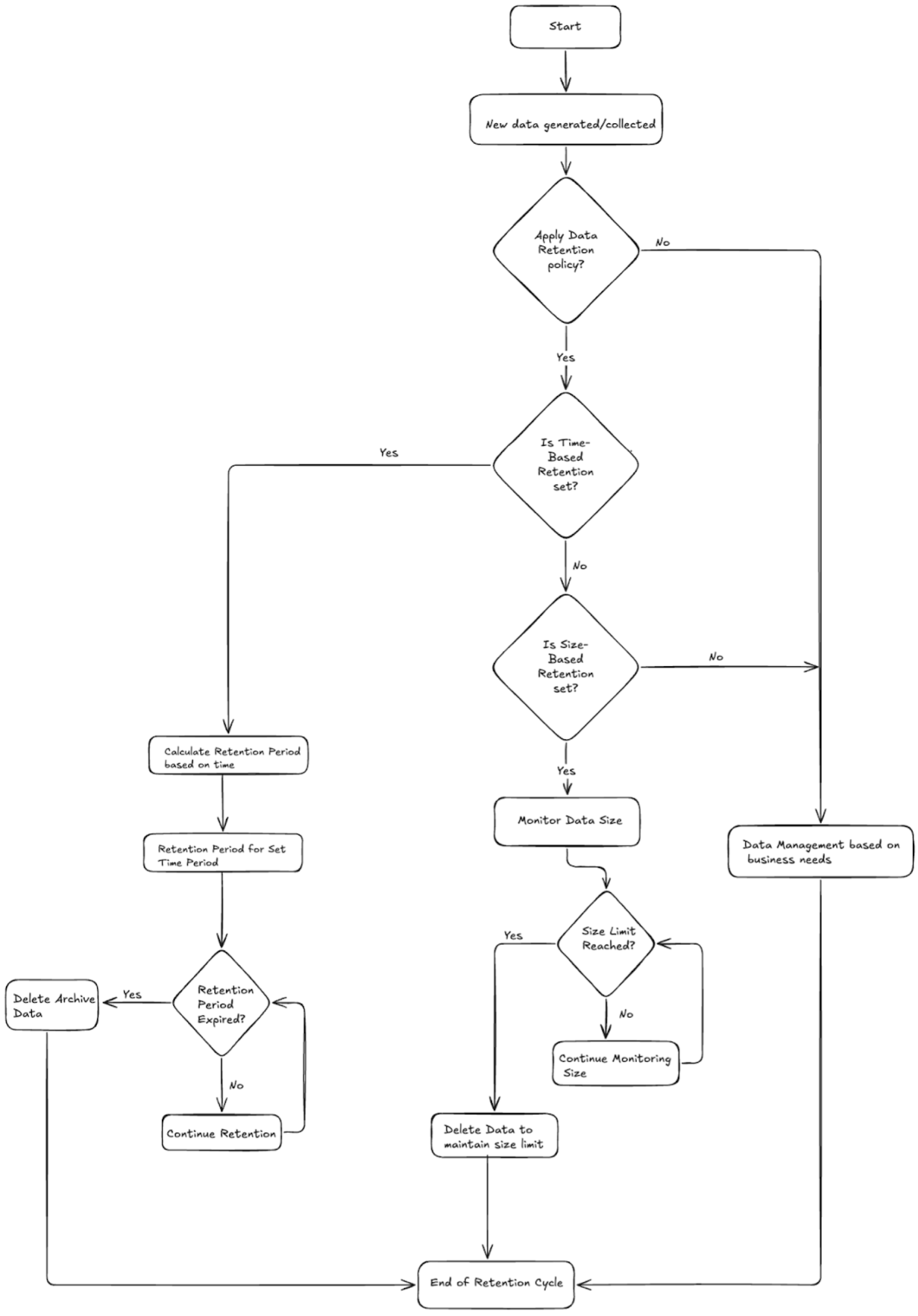
Common retention issues and fixes flowchart
Fixing Misconfigured Retention Policies
When retention policies conflict or produce unexpected behavior, follow a systematic approach to identify and resolve configuration issues:
# Step 1: Identify conflicting configurations
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name problematic-topic \
--describe
# Step 2: Remove conflicting settings
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name problematic-topic \
--alter \
--delete-config retention.hours # Remove conflicting parameter
# Step 3: Set correct retention policy
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name problematic-topic \
--alter \
--add-config retention.ms=604800000,retention.bytes=1073741824
Preventing Unexpected Data Deletion
Address premature data deletion by analyzing the interaction between different retention mechanisms:
# Check current segment sizes and ages
kafka-log-dirs.sh --bootstrap-server localhost:9092 \
--describe --json | jq '.brokers[].logDirs[].partitions[] |
select(.partition | contains("topic-name"))'
# Adjust segment rolling to prevent premature cleanup
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name topic-name \
--alter \
--add-config segment.ms=86400000 # Roll segments daily instead of by size
Managing Excessive Disk Usage
When topics consume more storage than expected, implement graduated response strategies:
# Immediate: Reduce retention period temporarily
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name high-usage-topic \
--alter \
--add-config retention.ms=259200000 # Reduce to 3 days
# Long-term: Implement size-based limits
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name high-usage-topic \
--alter \
--add-config retention.bytes=2147483648,segment.bytes=134217728
Proactive Monitoring and Alerting
Implement monitoring to catch retention issues before they impact operations:
Key Metrics to Monitor:
-
Partition size growth rates
-
Consumer lag trends
-
Disk usage per broker
-
Log cleanup frequency and duration
-
Error rates in broker logs
Sample Alerting Thresholds:
# Disk usage alert when partitions exceed expected size
partition_size_gb > retention_bytes / (1024^3) * 1.2
# Consumer lag alert indicating retention issues
consumer_lag_hours > retention_hours * 0.8
# Cleanup performance alert
log_cleanup_duration_ms > 60000 # Cleanup takes longer than 1 minute
Best Practices for Kafka Retention
A well-managed Kafka retention policy is not just about setting time or size limits—it's about aligning technical configurations with real business goals while keeping Kafka performant and scalable. Below are proven best practices for managing Kafka message retention effectively in production environments.
1. Audit Kafka Retention Configurations Regularly
Retention settings should evolve with your data lifecycle. Outdated configurations can lead to data loss, disk exhaustion, or performance bottlenecks.
Recommended Audit Cadence:
-
Monthly: High-volume or customer-facing topics
-
Quarterly: Operational or service telemetry topics
-
Annually: Regulatory and compliance logs
2. Align Retention with Business Requirements
Every data stream has a different lifecycle. Create a retention policy framework that categorizes topics by their business relevance:
-
Real-Time & Operational Data: Retain for 7–30 days for immediate use
-
Analytical & Historical Data: Retain 90–365 days based on reporting needs
-
Compliance Data: Retain 3–7 years based on regulatory requirements
Map these tiers to Kafka configurations using a mix of retention.ms, retention.bytes, and segment.bytes values. Avoid a one-size-fits-all retention window.
3. Monitor Retention Effectiveness & Disk Usage
Kafka’s log retention relies on background cleanup processes that must be monitored to ensure they’re functioning properly. Use metrics like:
-
Disk usage per broker
-
Log cleanup throughput
-
Consumer lag relative to retention window
-
Log segment growth rate
4. Adapt Retention Policies Dynamically
Kafka retention settings should scale with your system’s needs. Automate retention adjustments based on capacity signals like disk usage or seasonal data surges.
Example Use Case:
Retail platforms may extend retention during peak shopping periods and scale it back afterward to optimize costs.
Even basic shell scripts can trigger config updates based on disk thresholds, but tools like Confluent Control Center offer a more streamlined and scalable approach for dynamic retention adjustments.
5. Balance Storage Costs and Cluster Performance
Longer retention periods consume more disk and I/O, potentially slowing down Kafka’s performance. Best practice is to strike a balance between retention depth and operational efficiency:
Key Observations:
-
Retaining data for over 90 days increases disk usage linearly.
-
CPU and I/O pressure from compaction and segment cleanup grows non-linearly.
-
30–90 days is often the “sweet spot” for operational and analytical workloads.
Suggested Optimization:
-
Use larger segment sizes (e.g., 256MB+) for high-throughput topics.
-
Limit cleaner throughput with log.cleaner.io.max.bytes.per.second to avoid saturation.
How Confluent Streamlines Retention Management
Confluent Platform and Confluent Cloud provide enterprise-grade features that simplify retention policy management and monitoring.
Automated Retention Management
-
Confluent Cloud Autoscaling: Automatically adjusts cluster resources based on retention requirements and data volume, eliminating manual capacity planning for retention policies. Learn more about the benefits of autoscaling on Confluent Cloud.
Schema Registry Integration: Enforces data governance policies that work seamlessly with retention configurations, ensuring data evolution doesn't break retention assumptions. Learn more with Schema Registry documentation.
Advanced Monitoring and Alerting
- Confluent Control Center: Provides comprehensive retention monitoring with visual dashboards, alerting, and automated policy recommendations. The platform tracks retention effectiveness and suggests optimizations based on usage patterns.
- Tiered Storage: Confluent Cloud's tiered storage automatically moves older data to cost-effective cloud storage while maintaining seamless access patterns. This feature dramatically reduces storage costs for long retention periods. Tiered storage documentation.
Get Hands-On With Kafka Retention Best Practices
We’ve walked through the nuances of time- and size-based retention, compaction, tiered storage, and the operational steps to keep them in check. If there’s one takeaway, it’s this: treat retention as a living part of your Kafka design, not a set-and-forget setting.
Retention settings in Kafka aren’t just a checkbox in your topic configuration—they define how your platform balances performance, cost, and compliance over time. The right approach can keep clusters lean and responsive, allowing organizations to future-proof their data architecture for both innovation and reliability, while the wrong one can quietly drain storage, slow consumers, or even cause data loss.
Retention mastery is a journey, but each experiment sharpens your ability to design Kafka systems that are efficient today and resilient tomorrow. From here, the most valuable next step is hands-on practice. Set up a test environment, push real workloads, and watch how changes in retention settings ripple through storage usage and consumer behavior. Pair those observations with the monitoring tools you already use—or try Confluent’s built-in visibility—to turn theory into operational confidence.
Kafka Retention FAQs
1. What is Kafka retention?
Kafka retention defines how long messages are kept in a topic before they are deleted or compacted. It ensures storage is managed efficiently while keeping data available for consumers.
2. What are the types of Kafka retention policies?
Kafka supports time-based retention (keeping data for a set duration) and size-based retention (keeping data until the topic reaches a set size). Both can be combined for flexibility.
3. What is the difference between log deletion and log compaction in Kafka?
Log deletion removes entire segments once retention limits are reached. Log compaction retains only the most recent record per key, ensuring stateful data like user profiles is always available.
4. How do you configure Kafka retention?
Retention can be configured at the broker or topic level using properties like retention.ms, retention.bytes, and cleanup.policy. Topic-level configs override broker defaults.