[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
Horizontal vs Vertical Scaling in Apache Kafka®
Horizontal vs vertical scaling in Apache Kafka® is one of the most important considerations for teams running Kafka in production. As data volumes grow and more applications depend on real-time streaming, the way you scale your Kafka cluster directly impacts performance, cost efficiency, and operational complexity.
Learn trade-offs and best practices for scaling Kafka clusters to meet any use case requirements or workload demands.
Why Efficiently Scaling Apache Kafka® Clusters Matters
In simple terms:
-
Vertical scaling (scaling up) means upgrading existing brokers with more CPU, memory, or faster storage.
-
Horizontal scaling (scaling out) means adding more brokers to distribute workloads across a larger cluster.
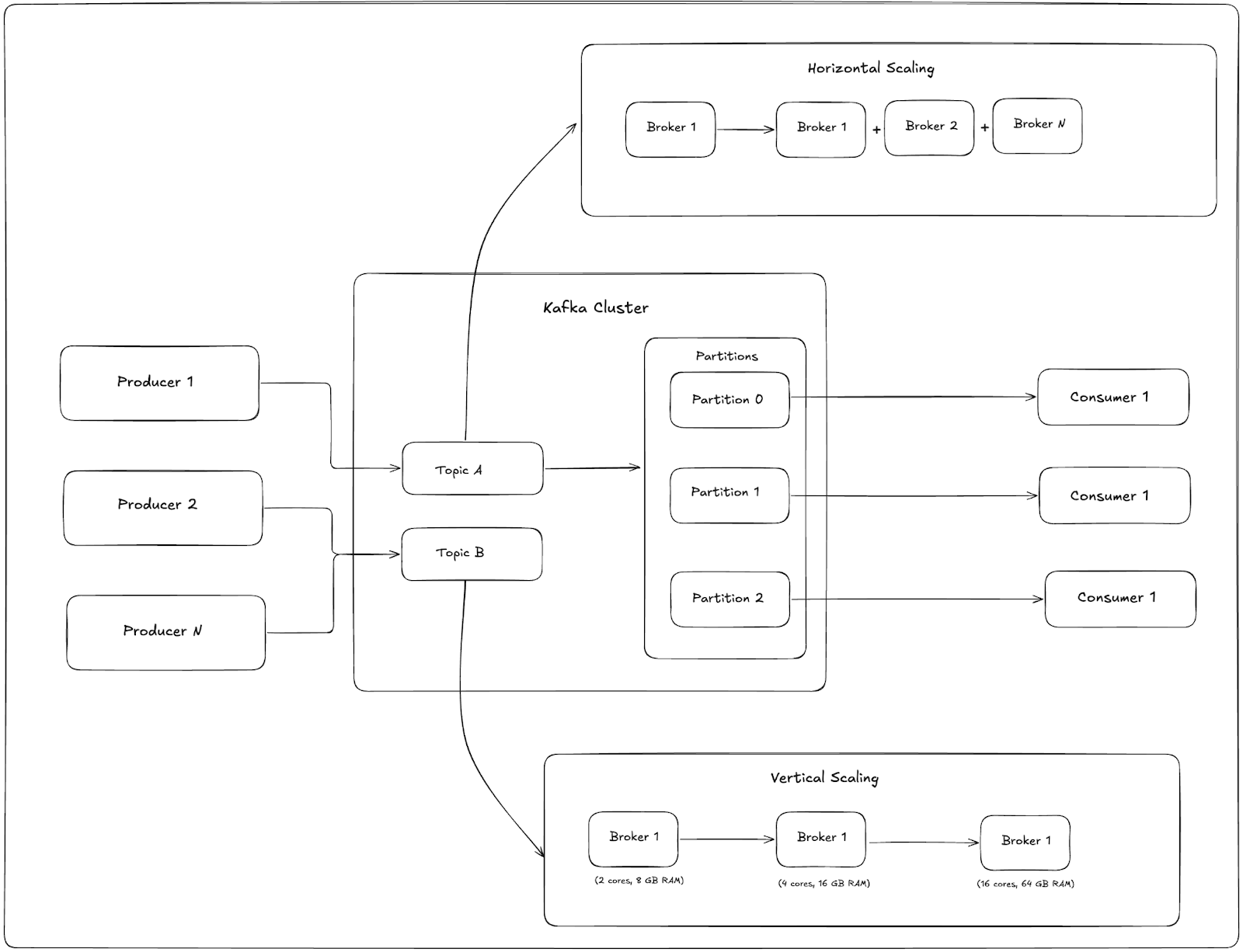
While both approaches can increase throughput and reliability, they come with different architectural patterns, operational implications, and cost trade-offs. Making the right choice early in your Kafka journey prevents performance bottlenecks, costly migrations, and downtime in production.
For example, vertical scaling can help in the short term when hardware resources are the limiting factor but physical limits are reached quickly. Horizontal scaling, on the other hand, aligns more closely with Kafka’s distributed architecture and leverages concepts such as Kafka partition strategy to distribute load effectively.
This article will break down the differences between scaling vertically and horizontally, explore the tradeoffs, and share best practices so you can choose the right strategy for your production environment.
Horizontal Scaling: Adding Brokers and Partitions
Horizontal scaling in Apache Kafka involves adding more brokers and partitions to your cluster. This approach distributes workloads across multiple machines, increasing capacity without overloading a single node. In production environments, organizations frequently scale Kafka horizontally to handle higher throughput and maintain service resilience as data volumes grow.
When you add brokers to increase throughput, Kafka can spread partitions across the new nodes, allowing more consumers and producers to operate in parallel. This scaling pattern provides linear throughput gains in many scenarios, especially when paired with an effective Kafka partition strategy.
Benefits of horizontal scaling:
-
Linear throughput improvement: More brokers and partitions mean parallel processing at scale.
-
Fault tolerance: Spreading replicas across more nodes reduces the risk of cluster-wide outages.
-
Reduction of hardware bottlenecks: Workload distribution prevents any single broker from becoming a performance choke point.
Kafka’s design allows horizontal scaling to be implemented incrementally. Teams can start small and optimize throughput by increasing partitions over time, following Confluent’s partition guidance docs. This elasticity makes it a preferred approach for businesses expecting rapid, unpredictable traffic growth.
Confluent Cloud combines vertical and horizontal scaling mechanisms with elastic autoscaling
Vertical Scaling: Bigger Brokers (CPU, Memory, Disk)
Vertical scaling means increasing broker resources for performance by upgrading CPU, memory, or storage on existing Kafka brokers or client applications (such as Kafka Streams). This approach improves the performance per instance, allowing a single broker to handle larger workloads before hitting resource limits.
When you scale Kafka vertically, the cluster benefits from faster message processing, higher partition density per broker, and reduced garbage collection (GC) or input/output (I/O) bottlenecks. This can also apply to Kafka client applications, where proper tuning based on workload patterns is key. The Kafka Streams sizing guide offers practical recommendations for right-sizing CPU, RAM, and disk for production-scale stream processing.
Advantages of vertical scaling:
-
Higher performance per broker: Handle more partitions and messages without adding nodes.
-
Simpler management: There are fewer brokers to monitor, patch, and upgrade.
-
Fast upgrade path: This is useful for short-term performance boosts before scaling out.
Limitations:
-
Hardware ceilings: Even the largest instances have performance limits.
-
Cost inefficiencies: High-performance hardware can be significantly more expensive.
-
Single-node risk: A bigger broker failing can impact more partitions.
While vertical scaling can deliver quick performance gains, it’s generally best paired with horizontal scaling for sustained growth and resilience.
Kafka Scaling Trade-Offs Table
When deciding between scaling Kafka horizontally (adding brokers and partitions) and scaling Kafka vertically (upgrading CPU, memory, or disk on existing brokers), it’s important to weigh cost, fault tolerance, complexity, and throughput impact.
|
Factor |
Horizontal Scaling (Add Brokers and Partitions) |
Vertical Scaling (Bigger Brokers) |
|
Cost |
Moderate to high: more instances but can use smaller ones |
High up front: premium hardware, larger instances |
|
Failure Domain |
Lower risk: partitions spread across more brokers |
Lower risk: fewer brokers to operate, simpler monitoring |
|
Operational Complexity |
Higher: more nodes to manage; must consider danger of too many partitions impacting batching and producer efficiency |
Lower: fewer brokers to operate, simpler monitoring |
|
Throughput Scaling |
Linear or near-linear: can scale Kafka horizontally to increase overall cluster capacity |
Improved per-node throughput: increased broker resources for performance but limited by hardware ceilings |
|
Best for |
Sustained growth, fault tolerance, large-scale workloads |
Short-term boosts, workloads with small broker count |
Both strategies can be complementary. Vertical scaling can address immediate performance bottlenecks, while horizontal scaling can ensure long-term growth and resilience.
When Vertical Scaling Helps (Client and Broker Use Cases)
While horizontal scaling is often the go-to for long-term growth, there are clear vertical scaling use cases in which upgrading hardware delivers immediate benefits.
-
Kafka Streams Stateful Applications:
Stateful stream processing apps, especially those with large state stores, are CPU- and memory-intensive. Before you split workloads into multiple instances, it may be faster and more cost-efficient to scale Kafka vertically by increasing CPU, memory, or disk input/output operations per second (IOPS). For examples of common Kafka Streams sizing scenarios, see the Kafka Streams sizing scenarios guide. -
Brokers Handling High Partition Density:
If a single broker is hosting a large number of partitions or has to serve high-throughput topics, adding more CPU, memory, or faster disks can alleviate bottlenecks without rebalancing the entire cluster. -
Temporary Performance Boosts Before Major Restructuring:
When workloads spike (e.g., seasonal traffic), vertical scaling can be a quick win to sustain performance while you prepare a horizontal scaling rollout.
When to scale Kafka vertically:
-
High CPU utilization due to message serialization/deserialization
-
Memory pressure from large consumer fetch sizes
-
Disk I/O saturation on brokers storing large topics
Vertical scaling is best when the performance issue is resource-bound and the cost or time to add brokers outweighs the immediate need for extra capacity.
Practical Guidelines and Best Practices
When scaling Kafka—whether horizontally or vertically—following a few proven rules of thumb can prevent bottlenecks and ensure balanced performance.
-
Partition Planning:
A good baseline is to keep partition count ≥ consumer count for each consumer group. This ensures that all consumers remain active and avoids idle clients. See the partition guidance docs for deeper recommendations for optimizing throughput by increasing partitions. -
Maximum Partitions per Broker:
As a recommended threshold, try not to exceed 2,000–4,000 partitions per broker in production environments, which can increase controller load and GC pressure, impacting stability. -
Resource Usage Targets:
-
CPU usage: Keep average load < 60% for headroom during spikes.
-
Memory usage: Maintain at least 20%–30% free heap for Java Virtual Machine (JVM)-based components.
-
Disk usage: Stay under 70%–80% to avoid premature log segment deletion.
-
-
Scaling Strategy:
Start with partition planning, then choose between horizontal or vertical scaling based on whether the bottleneck is resource-bound or architecture-bound.
By applying these Kafka scaling best practices, you can achieve predictable throughput, avoid consumer imbalance, and maintain fault tolerance without over-provisioning.
Case Studies and Real-World Examples
Walmart – Omnichannel Retail
Walmart leverages a large, distributed Kafka deployment to power real-time inventory and replenishment across thousands of stores and distribution centers. Its Kafka infrastructure includes at least 18 brokers and 20+ topics, each with 500+ partitions, enabling the processing of close to 100 million SKUs within a three-hour daily planning window.
Partitioning is the core enabler, allowing concurrent processing, linear throughput growth, and operational resilience against individual broker failures.
"We leverage 18 Kafka brokers and manage 20+ topics, each of which has more than 500 partitions ... Thanks to Kafka-backed real-time replenishment, [we] process close to 100 million SKUs ..., enabling timely and optimal availability across stores and warehouses."
— How Walmart Uses Kafka for Real-Time Omnichannel Replenishment
BMW Group – Automotive Manufacturing
BMW Group has built a central real-time data backbone on Confluent, integrating data from 30+ global production facilities and making it instantly available for analytics, quality control, and supply chain optimization. The Kafka clusters elastically scale via Confluent’s managed services, supporting SAP integration and industrial Internet of Things (IoT) protocols.
How to Decide Between Horizontal and Vertical Scaling in Kafka
Choosing the right scaling approach depends on workload characteristics, infrastructure limits, and team capabilities. This decision tree walks you through the key questions:
1. Is throughput growth the main driver?
Yes → Are you expecting sustained linear growth in traffic (e.g., more producers/consumers, more events per second)?
-
Yes → Horizontal scaling: Add brokers and partitions to handle more parallelism.
-
No → If growth is occasional or seasonal, explore auto-scaling in Confluent Cloud before hardware upgrades.
2. Are you hitting hardware constraints on a single broker?
Yes → Can your infrastructure support bigger brokers (more CPU cores, RAM, faster storage)?
-
Yes → Vertical scaling: Upgrade broker specs for quick performance boosts without changing partition layouts.
-
No → Horizontal scaling: Distribute load across additional brokers.
3. Is your workload stateful with heavy local processing?
-
Yes → (e.g., Kafka Streams with large state stores, heavy joins) → Vertical scaling is often simpler; more memory and CPU help avoid costly state rebalancing.
-
No → Stateless or light state workloads → Horizontal scaling works best for parallelism.
4. How skilled is the team with Kafka partitioning and rebalancing?
-
Advanced skills → Horizontal scaling can be tuned for high throughput and low latency.
-
Limited skills → Vertical scaling may be less disruptive in the short term, especially for smaller teams.
Quick rule of thumb:
-
Horizontal scaling → Best for throughput growth, fault tolerance, and distributed teams
-
Vertical scaling → Best for CPU- and memory-bound stateful workloads and quick wins when broker count is already optimal
Summary and Next Steps
Kafka Scaling Summary Table
|
Dimension |
Horizontal Scaling |
Vertical Scaling |
|
Method |
Add brokers and partitions. |
Increase CPU, RAM, or storage on existing brokers. |
|
Best for |
High throughput, resiliency, distributed workloads |
Stateful apps, performance tuning within a single broker |
|
Fault Tolerance |
Higher: Failures are absorbed by cluster. |
Lower: Hardware is a single failure domain. |
|
Operational Complexity |
Higher: partition management, rebalancing |
Lower: simpler to implement |
|
Cost Model |
Pay as you grow with infra footprint |
Higher per-node cost, limited by hardware ceilings |
|
Real-World Fit |
Next Steps
-
Learn from partition guidance docs to optimize throughput by increasing partitions.
-
Review the Kafka Streams sizing guide for vertical scaling best practices.
-
Understand the dangers of too many partitions impacting batching and producer efficiency before scaling out.
-
Explore real-world case studies like BMW Group’s central data backbone with Confluent.