[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
Building a Real-Time Application: The Ultimate Guide
Building a real-time application means processing and responding to data as events happen, enabling businesses to act on information within milliseconds rather than hours or days. This guide walks you through creating a real time app using Apache Kafka® and Apache Flink® for data streaming and processing, starting with a practical example to explore broader architectural concepts.

TL;DR: Build a real-time app by streaming events into Kafka, processing them continuously with Flink, Kafka Streams, or ksqlDB, and serving results to your application or database—using Confluent Cloud for managed operations, governance with Schema Registry, and pre-built integrations.
What Is a Real-Time Application (and How Is It Different From batch?)
A real-time application processes data in motion, responding to events as they occur and are generated by business systems. In contrast, traditional applications collect and process data in batches. The fundamental distinction between batch vs. real-time processing lies in data latency: batch systems operate on hours-old or days-old data, while real time web applications respond within milliseconds to seconds.
Batch applications collect data over time intervals, process it in bulk, and produce results on a scheduled basis. The challenge? Imagine you have a nightly ETL job that aggregates sales data —any decisions made the next morning rely on yesterday's information, leaving your organization behind the curve.
When a user clicks "buy," the backend fraud detection system needs to evaluate the transaction instantly in order to provide adequate protection to the customer and the business. When a sensor detects an anomaly, alerts should trigger immediately. This kind of responsiveness can prevent millions in losses. Simiarly, real-time data can power dynamic pricing systems that optimize revenue by responding to demand fluctuations, operational monitoring that prevents downtime by catching issues in their early stages, and much more.
“With Wix Analytics, the value of user feedback is tremendous for our customers’ developers. That’s what differentiates us from other platforms, and Confluent makes it possible, in real time and at massive scale. We frequently hear that those real-time insights are what keep us the preferred platform for some of our longest-standing customers. The ability to know what is happening in your business—especially a virtual business—as near to real time as possible is invaluable for Wix and for its users.”
— Josef Goldstein, Head of R&D, Big Data Platform,Wix
What Components Do You Need to Build a Real-Time App?
Building a real-time application requires several integrated components of a data streaming platform that work together to capture, process, and deliver streaming data efficiently.
A production-ready real-time application typically includes:
-
Event streaming platform: Kafka provides durable event storage, publish-subscribe messaging, and stream replay capabilities
-
Stream processing layer: Flink executes continuous queries, stateful computations, and event-time processing
-
Data integration: Connectors link Kafka to external systems (databases, cloud storage, SaaS applications)
-
Schema Registry: Manages data contracts and ensures compatibility across producers and consumers
-
Monitoring and observability: Tracks throughput, latency, consumer lag, and processing errors
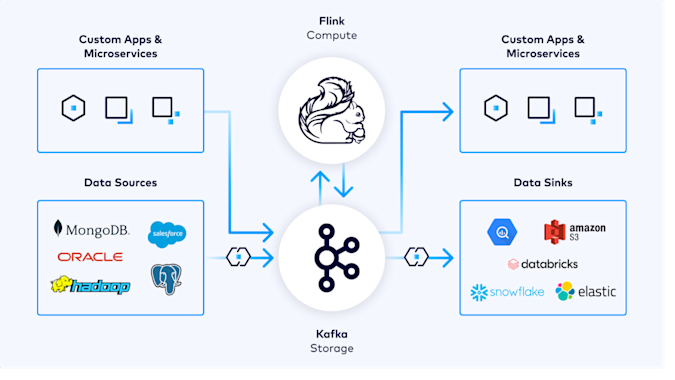
In a real-time application architecture, data flows between event sources, Kafka, Flink, and event sinks or destinations
Event Streaming With Apache Kafka
Kafka acts as the event streaming backbone, ingesting data from multiple sources, stores it in a distributed, fault-tolerant manner, and makes it available for real-time processing. It can handle millions of events per second, ensuring ordering guarantees and durability across the system.
Stream Processing Engines
To transform raw event streams into actionable insights, stream processing engines are used. Both Apache Flink and Kafka Streams provide stateful stream processing respectively with exactly-once semantics. Flink is more suited for advanced processing, supporting complex event processing patterns, windowing, and joins across multiple streams. For developers who prefer SQL, ksqlDB offers SQL-based stream processing, enabling declarative queries over streaming data.
Confluent Cloud unifies Kafka and Flink in a serverless experience that makes it easier to cut Kafka platform engineering and development costs, shift governance and processing left (i.e., closer to the source), prevent bad data proliferation, and cut down on expensive reprocessing.
Stateful Storage
Processed results and application state are persisted in stateful storage layers, such as PostgreSQL or other databases. These storage systems integrate with streaming pipelines, providing queryable snapshots of the current system state for downstream applications.
What Does a Real-Time Architecture With Kafka and Flink Look Like?
Event-driven architecture principles guide real time web application design. Rather than requesting data through synchronous API calls, components react to events as they flow through the system. This decoupling enables independent scaling, fault isolation, and flexible composition of processing logic.
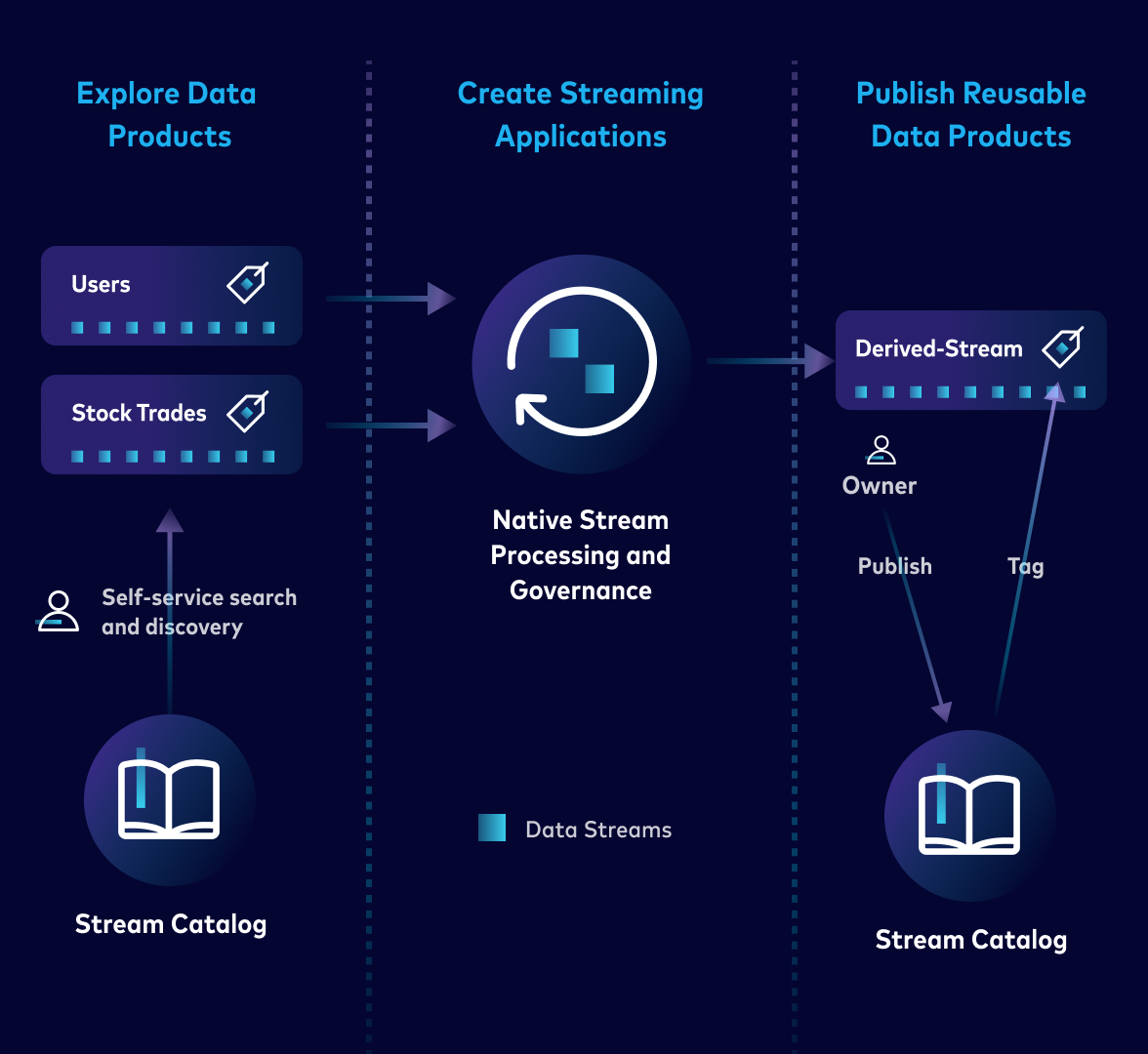
How Does Data Flow Through a Real-Time Application Stack?
The layered view of this architecture shows: producers generating events → Kafka distributing and storing streams → Flink performing continuous processing → applications and AI systems consuming results. Each layer operates independently, communicating through well-defined interfaces.
Modern architectures often incorporate data governance frameworks and streaming lakehouse patterns to ensure that fresh, high-quality data reaches its intended destination securely, at scale, and ready to use.
Together, Kafka connectors and Confluent Tableflow enables seamless integration between the operational and analytical estates. Confluent’s pre-built and fully managed connectors allow teams to more easily move data between external systems and Kafka, while Tableflow—which materialized streams as Apache Iceberg ™ and Delta Lake tables—allows those streams to actually become a true single source of truth for both real-time and historical analysis.
How Do You Build a Real-Time Application With Kafka?
Let’s create a real-time order management application that monitors and analyzes incoming orders and calculates key metrics like total orders, total sales, and average order value per region. This example demonstrates the core pattern you’ll use for any real-time application: producers feed events into Kafka, stream processors transform data in motion, and consumers deliver insights in real time.

Data Movement Pattern for a Real-Time Order Management Application
Step 1: Create a Confluent Cloud Environment and Kafka Cluster
Start by signing up for Confluent Cloud or logging in:
-
Create a new environment and Kafka cluster (Basic or Standard).
-
Note your Bootstrap Server, API Key, and API Secret.
-
Enable Schema Registry in the same environment—create API Key, and API Secret for Schema Registry.
This fully managed setup forms the backbone of your real-time application development environment.
Step 2: Produce Events to Kafka
Create a producer that sends order events into Kafka in real-time. Each event contains order_id, user_id, amount, and region. (See the Kafka Python Guide for Kafka on Confluent Developer for sample code to follow.)
Key points:
-
Use Avro with Schema Registry for structured, consistent messages.
-
Keys ensure events for the same order_id go to the same partition (maintains order).
-
Randomized order generation simulates live traffic for testing.
Step 3: Create a Flink Compute Pool
Navigate to your Confluent Cloud environment and create a Flink compute pool. Select the same region and cloud provider as your cluster, then choose a compute pool size based on your processing needs. For this example, a small pool suffices.
Step 4: Process Events With Flink SQL
Use Flink SQL to process events in real time. In the Confluent Cloud Console, open the Flink workspace and create a new SQL statement to calculate engagement metrics.
First, create a table that maps to your Kafka topic:
/*
This creates a table that maps to your Kafka topic
*/
CREATE TABLE orders_summary (
region STRING PRIMARY KEY NOT ENFORCED,
total_orders BIGINT,
total_sales DOUBLE,
avg_order_value DOUBLE
)
WITH (
'changelog.mode' = 'upsert'
);
Now compute live metrics such as total orders, total sales, and average order value per region:
/*
This computes live metrics summarizing order details
*/
INSERT INTO orders_summary
SELECT
region,
COUNT(*) AS total_orders,
SUM(amount) AS total_sales,
ROUND(AVG(amount), 2) AS avg_order_value
FROM orders_raw
GROUP BY region;
Flink SQL abstracts the complexity of stream processing so you can write declarative queries instead of manual stream processing code. Metrics are updated in real-time as new orders arrive. The results automatically flow to a new Kafka topic that you can consume in your application.
Step 5: Consume and Display Results
Create a consumer that reads processed metrics and displays them in your real-time application dashboard or triggers alerts based on engagement thresholds. (See the Kafka Python Guide for Kafka on Confluent Developer for sample code to follow.)
Which Use Cases Benefit Most From Real-Time Apps?
So far you’ve:
-
Created a Kafka Producer: Continuously generates order events (order_id, user_id, amount, region).
-
Created a Kafka topic: Stores streaming order data reliably.
-
Used Flink SQL: Computes real-time aggregates per region.
-
Created Consumer: Reads and displays metrics in real-time.
You can now extend this foundation to:
-
Scale to millions of orders per second.
-
Implement complex analytics like fraud detection or churn prediction.
-
Integrate with AI models for real-time decisioning.
This approach to real-time data processing powers transformative capabilities across industries, enabling organizations to act instantly on streaming information including:
Fraud Detection in Finance
Financial institutions use real-time event processing to monitor transactions, user behavior, and contextual signals. Every payment is evaluated against current risk models, allowing banks to identify suspicious activity within milliseconds and prevent fraudulent transactions before they are completed.
IoT Monitoring and Automation
IoT applications ingest telemetry from sensors, machinery, and connected devices to enable proactive monitoring and automation. Manufacturing plants can detect equipment anomalies before failures occur, smart city systems optimize traffic flow based on live conditions, and energy grids dynamically balance load distribution in response to demand fluctuations.
Operational Dashboards
Real-time dashboards provide instant operational visibility across business functions. eCommerce platforms track inventory, orders, and customer behavior as it happens. Logistics companies monitor shipment status and delivery performance, while customer service teams can view live interaction metrics to manage capacity efficiently.
AI/ML Model Scoring
Real-time architectures enhance AI/ML capabilities. Models consume fresh features from streaming data, producing predictions that reflect the latest context. Recommendation engines update suggestions based on current user activity, and anomaly detection models adapt to evolving patterns in real time.
Additional applications span personalization engines, real-time analytics, operational intelligence, and event-driven microservices. Confluent’s real-time use cases library provides detailed examples and reference architectures across retail, finance, telecommunications, and other sectors.
Why Run Real-Time Apps on Confluent vs. a DIY Kafka Platform?
Building real-time infrastructure from scratch requires significant engineering investment. Open source Apache Kafka demands expertise in distributed systems, capacity planning, security hardening, and operational maintenance.
Confluent simplifies your path to production. Confluent Cloud provides fully managed Kafka clusters with automatic scaling, zero-downtime upgrades, and built-in security. The platform reduces operational complexity, allowing teams to deploy streaming applications without dedicated infrastructure specialists. And as a result:
-
Total cost of ownership decreases. Organizations avoid hardware provisioning, 24/7 operational staffing, and the engineering overhead of maintaining a distributed system like Kafka. All while Confluent handles cluster tuning, performance optimization, and disaster recovery procedures.
-
Native integrations accelerate development timelines. Confluent Hub offers pre-built connectors for hundreds of data sources and sinks—cloud databases, data warehouses, message queues, and SaaS platforms. These certified connectors reduce integration effort from weeks to hours.
-
Enterprise features are readily available to meet production requirements: role-based access control, encryption at rest and in transit, audit logging, multi-region replication, compliance certifications, and more.
Start Building Your Real-Time Application Today
Real time applications transform business capabilities by enabling immediate response to events, delivering superior user experiences, and unlocking new operational efficiencies. Apache Kafka and Apache Flink provide the foundation for scalable, reliable event-driven architectures.
Sign up for Confluent Cloud free to start building. The platform includes $400 in credits, managed Kafka clusters, stream processing capabilities, and pre-built connectors—everything needed to create your first real time app without infrastructure complexity.