[2026 Predictions Webinar] How to Build an AI-Ready Data Architecture This Year | Register Now
Accelerate Your Cloud Data Warehouse Migration and Modernization with Confluent
Cloud has drastically changed the data analytics space as organizations have decoupled storage from compute to power new analytics, ranging from traditional BI to machine learning (ML). As organizations migrate their analytics data from existing on-prem data analytics platforms like Teradata, Cloudera, and mainframes, they are adopting cloud data warehouses like Snowflake, Databricks, BigQuery, Redshift, and Synapse. For many organizations, using a single-region, cloud provider, or data warehouse isn’t in the cards.
As lines of business spin up new small-scale data warehouses, acquisitions bring their own technology, or agile teams spin up the data warehouse of choice, developers and enterprise architects need to have the flexibility to connect the web of data that lives on-prem and across the clouds. While all that happens, enterprises also want a solution that helps migrate them to the cloud of their choice, connecting data from any source system, while maintaining the flexibility and security to work across multi-cloud and hybrid environments.
Enterprises like KeyBank, Nuuly, Sky Holiday, and Rodan + Fields have all partnered with Confluent and the cloud provider of their choice to tackle this challenge head-on. As organizations rethink their data warehouse strategy, they also have an opportunity to rethink how they build data pipelines. Specifically, they can use open source standards to power real-time ETL to connect data, reduce costs, and improve time to value.
Regain your freedom of choice with Confluent’s hybrid and multi-cloud data warehouse modernization solution
Migrating your on-prem data warehouse or connecting data warehouses across clouds to unlock innovation doesn’t need to be a multi-year project. With Confluent’s data warehouse modernization solution, enterprises can create a bridge across clouds (Azure, AWS, Google Cloud) and on-prem environments to start moving data immediately while unlocking additional value. Pairing Confluent with your data warehouse helps you:
- Reduce the TCO and time to value of hybrid and multi-cloud data pipelines powering real-time ETL for your data warehouse
- Unlock next-gen event streaming capabilities at cloud scale to power new analytics and real-time apps
- Connect to any app, data warehouse, or data store, no matter where it lives, to get more data to and from your data warehouse
See our solution in action with this demo!
Reduce the TCO of your data warehouse
Confluent helps improve the TCO and time to value of your data warehouse by leveraging the familiarity and existing footprint of Apache Kafka, as well through the ability to preprocess data prior to it landing in your cloud data warehouse. We help remove the complexities of deploying, scaling, tuning, and managing streaming data to make it easier and faster to build real-time pipelines across any environment. With Confluent Cloud, customers increase speed to market by up to 75%, and reduce total cost of ownership by 60%.
However, our solution goes far beyond fully managing Kafka. Confluent allows you to preprocess the data in stream with ksqlDB through simple SQL statements to reduce the footprint of the data prior to it landing in your data warehouse. You can have unlimited events stored and processed in Confluent to manage the costs associated with going from source to data warehouse. Resource-intensive data warehouse jobs can also be pushed down into the stream for certain use cases that require low-latency processing. What could take a traditional data warehouse minutes to complete can now be done in milliseconds, powering materialized views, aggregating (e.g., windowing), and large-scale table joins at scale.
Scale your event streaming and processing
High throughput, low-latency data processing is at the heart of Confluent’s platform for data in motion. As more of the world (both physical and virtual) becomes instrumented and real-time data is used to power new analytics and applications, it’s critical that you build on a foundation that can help you scale to meet your current and future real-time needs.
Confluent’s benchmarks against other messaging brokers show that our core open source technology—Apache Kafka—delivers the best throughput while providing the lowest end-to-end latencies up to the 99th percentile. This core performance—alongside our suite of fully managed, enterprise-grade capabilities such as Stream Governance, connectors, and Cluster Linking—makes Confluent a leading solution to make real time a real piece of a data warehouse strategy.
Connect to any data warehouse, app, or data source no matter where it lives
Building connectivity between all your distributed data, apps, and data warehouses is not a trivial task. With Confluent’s rich ecosystem of 120+ connectors that span across clouds and on-prem, enterprises can quickly access the data necessary for their data warehouse use cases. These pre-built, expert-certified connectors integrate with Kafka rapidly, freeing resources from ~12-24+ engineering months of designing, building, testing, and maintaining highly complex integrations.
By building the bridge from on-prem to the cloud once, you can reuse the same network, account, and security permissions for all future connections. With CDC (change data capture) capabilities built directly into certain connectors, you can keep your environment in sync to support your hybrid strategy.
When data flows through Confluent, you can send that data in real time not only to your data warehouse, but also to any application, microservice, or data store that needs it. This improves the ROI of your analytics data without having to incur the “double taxation” of having to move the data with your ETL tool, landing the data in a database or data lake, copying it over to your data warehouse, and then feeding it to the real-time application.
Get started on the cloud data warehouse of your choice!
Confluent’s data warehouse modernization solution works with any cloud data warehouse. Building upon your existing Confluent or open source Kafka footprint, Confluent can help you migrate (and pre-consolidate) your data from any on-prem data store and move it into your new cloud based data warehouse.
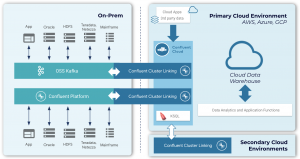
With Confluent Platform (our on-prem offering), you can define standard schemas within your Kafka clusters using Schema Registry, and use ksqlDB to access or transform your data easily. Then, create a cluster link to your Confluent Cloud instance running in your cloud service provider(s) (AWS, Azure, GCP, etc.).
For open source Kafka users, Confluent’s Cluster Linking technology allows you to reach into on-premises Kafka clusters from Confluent Cloud and create an easy-to-use bridge to bring data into Confluent Cloud in your cloud service provider. You set up security and networking once and reuse this persistent bridge every time you want to move data across environments.
Choose one of the following to see how this works on your cloud provider.
Microsoft Azure – Synapse and Databricks
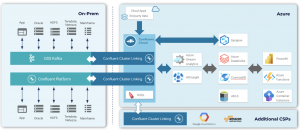
With all your transformed, preprocessed (or full fidelity!) data within Confluent Cloud, use the Azure Synapse connector to stream data from Kafka topics to Azure Synapse Analytics. The Azure Synapse connector loads to a dedicated SQL pool, which is then attached to Azure Synapse Analytics workspace. Leveraging Confluent Cloud and Azure Databricks as fully managed services in Microsoft Azure, you can implement new real-time data pipelines with less effort and without the need to upgrade or configure your datacenter. You can also analyze the cleaned and merged data with Synapse or Databricks using the Spark Structured Streaming APIs.
Cluster Linking can also be used to bring in data from other third-party cloud service providers and cloud data warehouses. With the data streaming to Synapse, you can take advantage of all the data warehousing, analytics, and function building capabilities Microsoft Azure has to offer—from Azure Stream Analytics to Azure Functions, and much more.
Additional resources
- Get started: Technical Overview Guide
- Demo: Data Warehouse Modernization with Azure
- Marketplace: Confluent on Azure Marketplace
Google BigQuery
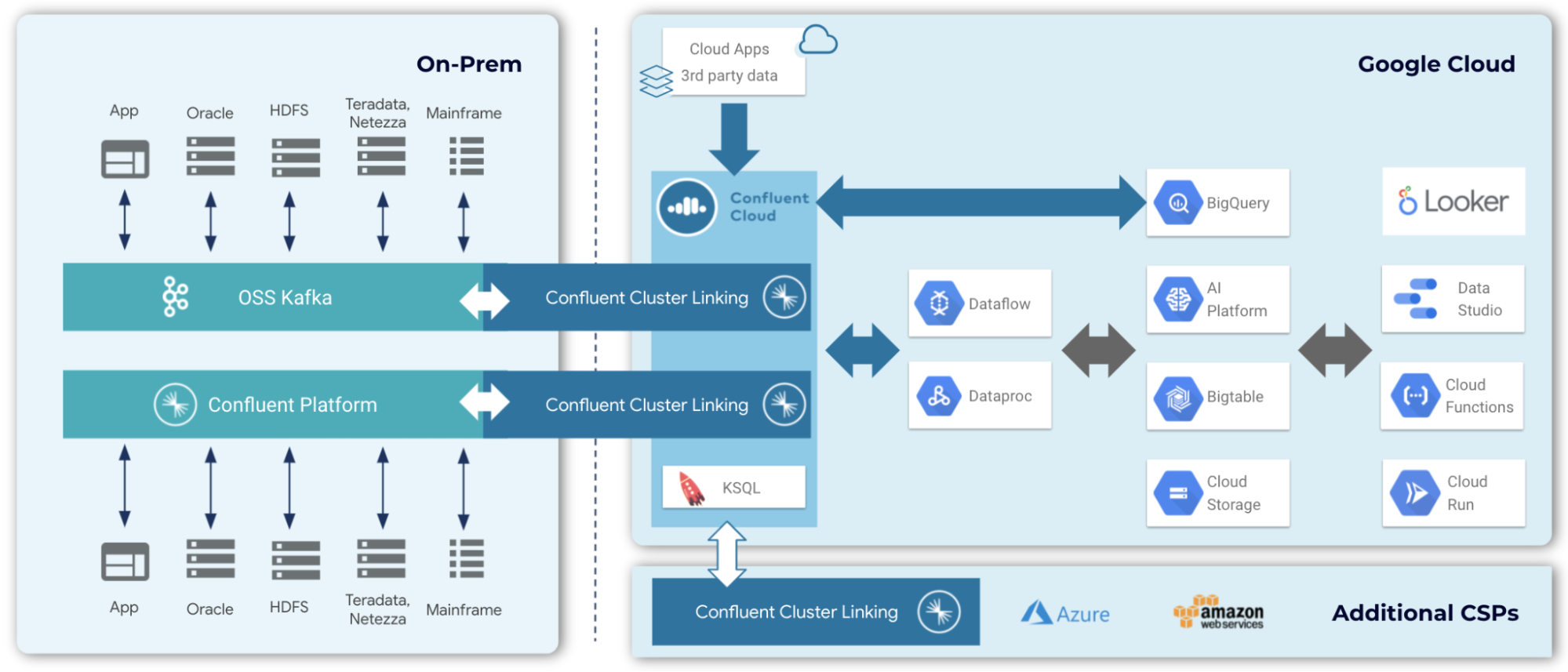
Use the Google BigQuery Sink connector to stream data to Google BigQuery and stream data into BigQuery tables. Google BigQuery is a serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility. Within BigQuery, data can be used to build and operationalize ML models on planet-scale structured or semi-structured data with BigQuery ML or interactively analyzed with BigQuery BI Engine. Once added to BigQuery, the data in the Confluent pipeline will be immediately available for analysts to have the ability to perform advanced analytics and reporting. The ability to access event-level data, enables event-level analytics and data exploration.
Cluster Linking can also be used to bring in data from other third-party cloud service providers and cloud data warehouses. With the data streaming to BigQuery, you can take advantage of all the data warehousing and smart analytics capabilities Google Cloud has to offer—from AI platform to cloud functions, and much more.
Additional resources
- Get started: Technical Overview Guide
- Demo: Data Warehouse Modernization with Google
- Marketplace: Confluent on Google Marketplace
Amazon RedShift
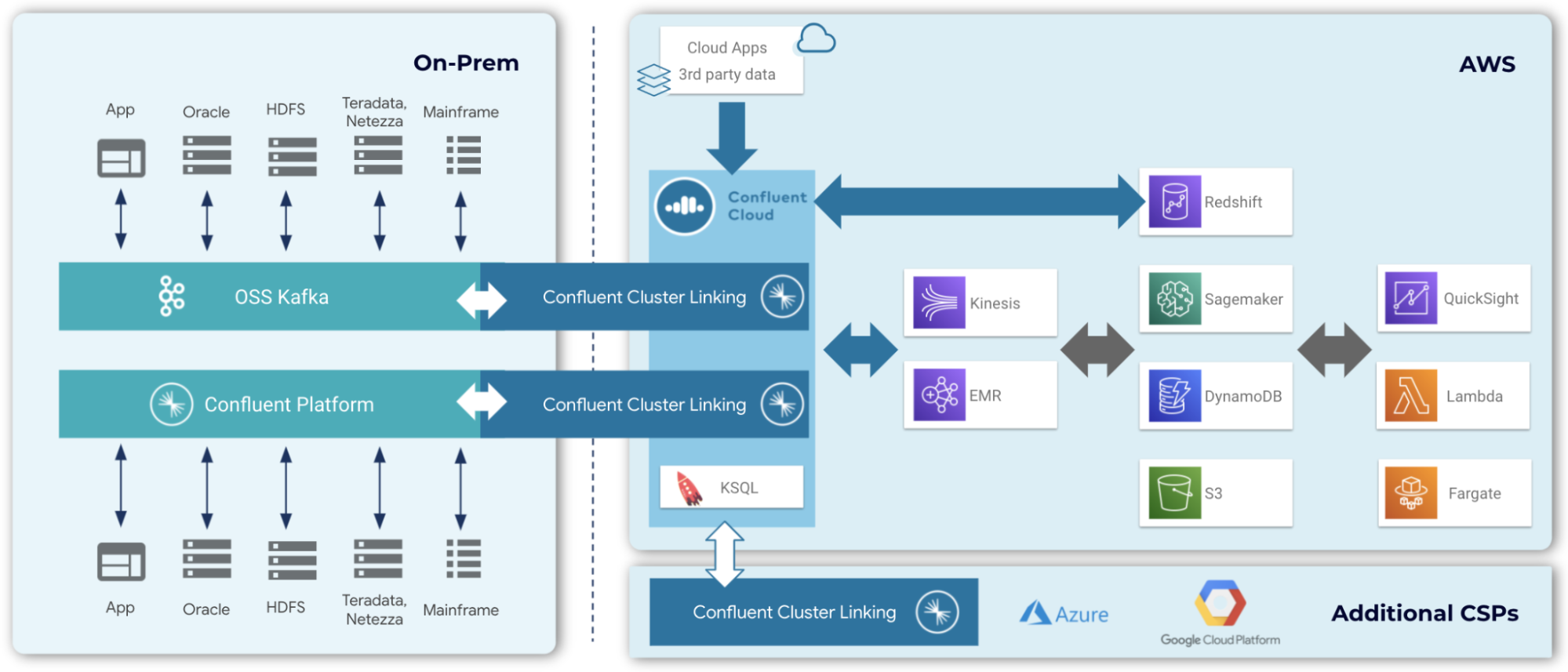
With all your transformed, preprocessed data within Confluent Cloud, use the Amazon Redshift connector to export Avro, JSON schema, or Protobuf data from Kafka topics to Amazon Redshift. The connector pulls data from Kafka and writes this data to an Amazon Redshift database. Pulling data is based on subscribed topics. Auto-creation of tables and limited auto-evolution are supported.
Additional resources
Next steps – Modernize your Cloud Data Warehouse with Confluent
Whether you are migrating a data warehouse to the cloud, connecting multiple data warehouses together, or optimizing your existing cloud data warehouse, Confluent can meet you where you are. To jump-start your journey please check out the resources below:
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Cost to Build a Data Streaming Platform: TCO, Risks, and Alternatives
Discover the real cost of building a data streaming platform in-house. Learn what drives expenses, compare to managed solutions, and see how to optimize total cost of ownership for platforms powered by Apache Kafka®.



Empowering the Data Streaming Ecosystem: Evolving Confluent Hub to Confluent Marketplace
Confluent Hub has evolved into the new Confluent Marketplace—a curated catalog when you can discover, purchase, and deploy community and partner-built integrations and streaming solutions.