[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
How to Find, Share, and Organize Your Data Streams with Stream Catalog
In a modern data stack, being able to discover, understand, organize and reuse data is key to obtaining the most value from your data. These requirements have led to the notion of a data catalog, which provides a centralized view of metadata for a modern data stack. At Confluent, where we’re focused on data streaming and applications built around data in motion, the entities that we’re interested in are Apache Kafka® topics, their corresponding schemas, and the use of topics by Kafka streams, ksqlDB streams/tables, and Kafka connectors. The Confluent Stream Catalog can be used to track all metadata about such data-in-motion and allow users to:
- Search and discover in a self-service way what data is available to use and re-use
- Share knowledge with others by enriching the entities on the catalog with extra contextual metadata in the form of tags, descriptions, and business metadata
- Organize, group, and classify data in compliance with different data regulations
As organizations scale and grow Kafka and real-time data streaming, one of the main challenges they face is how to govern all this data within the context of growing complexity and decentralized data management. Confluent’s Stream Catalog, one part of our larger Stream Governance suite, is the answer to unlocking the expansion of streaming to data practitioners across your organization, and enabling your business to become truly event driven.
The core of Confluent’s Stream Catalog
At the core of Confluent’s Stream Catalog is Apache Atlas, which we extended and adapted to the specificities of data-in-motion while making it available as a cloud-native service in Confluent Cloud. Apache Atlas is a popular open-source project that provides a set of scalable, extensible, and integrated governance services. Internally, Apache Atlas represents metadata using an entity-relationship model, and it is mainly this key component of Apache Atlas that is used by our Stream Catalog. The entity-relationship model provides a declarative means of adding new metadata to the catalog and supports many useful features, including a rich type system, bidirectional relationships, cascading delete, etc. The entity-relationship model is itself built upon a graph database called JanusGraph, which supports the Apache Tinkerpop graph computing framework.
Besides entities and their relationships, Apache Atlas also has support for higher-level governance features, including the ability to tag or classify entities, and the ability to augment entities with business metadata. For example, we offer a tagging feature that allows you to annotate schemas or their elements in the catalog with a PII tag. In the future, Confluent will be extending these governance features to other entities besides schemas, such as topics, connectors, ksqlDB queries, etc.
Interacting with Stream Catalog
When using the Confluent Cloud UI to search for schemas, you are interacting with the Confluent Stream Catalog. However, Stream Catalog also provides two other APIs besides the UI: a REST API and a newly released GraphQL API.
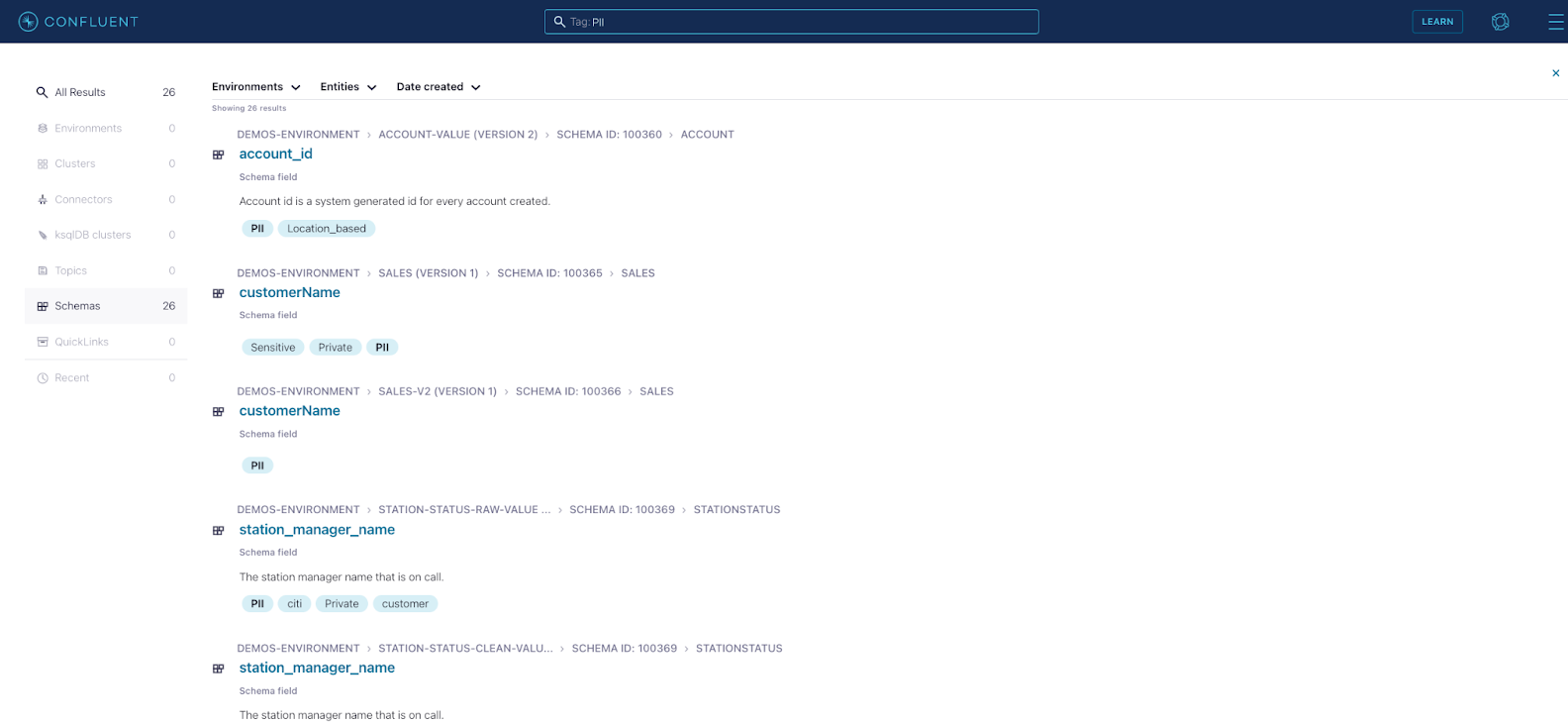
Searching for schema fields via the Confluent Cloud UI
The Stream Catalog REST API
The Confluent Stream Catalog provides a REST API that has been adapted from that of Apache Atlas. The REST API allows you to:
- Search for entities
- Create tag definitions
- Tag entities with tag definitions
- Create business metadata definitions
- Augment entities with business metadata
- And more!
We’ll be continually adding to this list to grow the capabilities of Stream Catalog over time.
Today, all schemas and their constituent parts are automatically cataloged in real time, i.e., every time a schema is created, evolved, or deleted. With the REST APIs, you can search for components of a schema, such as records or even individual fields. Furthermore, you can use the REST APIs to tag each component of a schema. For example, you can tag a field that contains Social Security numbers as PII as a result of data regulations compliance requirements, internal categorization policies, or simply to help with self-service search, discovery, and reuse of PII data across the platform. Tags are automatically propagated to subsequent versions of a schema, so that if you evolve a schema by adding a new field, the fields that were tagged in the old schema will retain their tags in the new schema.
For example, you can use the REST APIs to search for a field named “myField” as follows:
curl -u ${API_KEY}:${API_SECRET} 'https://psrc-xxxxx.region.provider.confluent.cloud/catalog/v1/search/attribute?type=sr_field&attrName=name&attrValuePrefix=myField' | jq .
The Stream Catalog GraphQL API
As mentioned, Stream Catalog uses the entity-relationship modeling capabilities of Apache Atlas, which is itself stored in a JanusGraph graph database. After all, a catalog is naturally an interconnected graph of entities, and a data-in-motion, event-based architecture makes these interconnections even more salient.
Due to the graph-related nature of metadata in the catalog, and in response to customer demand, we’ve added a GraphQL API atop Stream Catalog. The GraphQL API allows you to take advantage of the graph nature of GraphQL when querying the catalog, so that you can easily query for related entities across several relationships in the entity-relationship model.
GraphQL is supported by a number of tools, including the GraphQL Playground, shown below:
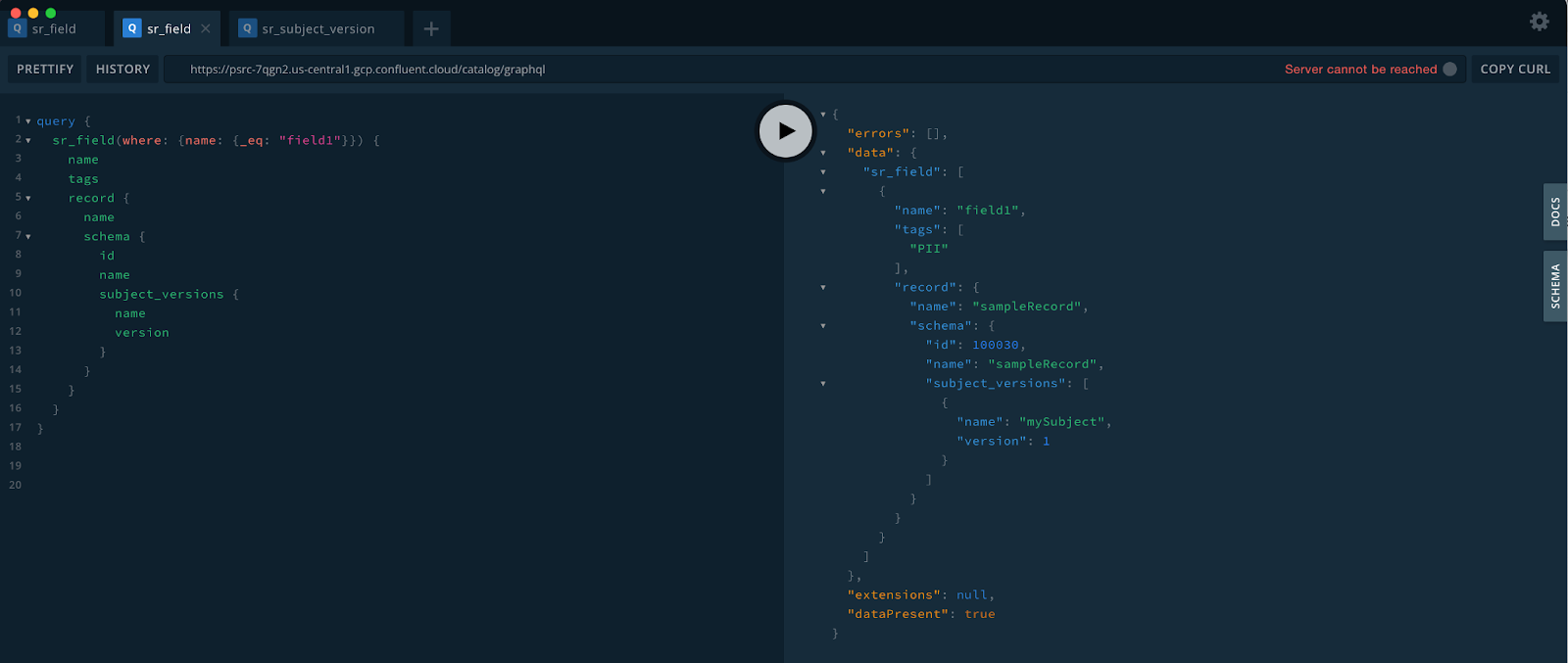
Using GraphQL, you can easily fetch an entity and its relationships. Using the previous example of searching for a field named “field1”, you can use the GraphQL query below to also retrieve the record, schema, and subject corresponding to the field by traversing the relationships from a field to its containers.
query {
sr_field(where: {name: {_eq: "field1"}}) {
name
tags
record {
name
schema {
id
name
subject_versions {
name
version
}
}
}
}
}
You can also traverse relationships in the reverse direction. In the GraphQL query below, we traverse from the subject to the field. Note the use of the GraphQL inline fragment (denoted by the …) with type condition sr_record. The inline fragment is needed because an sr_schema can contain different sr_type types, of which sr_record is only one such type. Inline fragments are how GraphQL specifies which concrete type of interface is being requested. Here the concrete type is sr_record and the interface is sr_type.
query {
sr_subject_version(where: {name: {_eq: "mySubject"}}) {
name
version
schema {
id
name
types {
... on sr_record {
name
fields {
name
}
}
}
}
}
}
Note that above we pass a where clause to the GraphQL query. The where clause supports a number of operators, including _eq, _gt, _lt, _gte, _lte, _starts_with, _between, and _since. In addition to the where clause, you can pass clauses to specify the limit, offset, order_by, tags, and deleted. For more information, see the Confluent Stream Catalog GraphQL API documentation. Feel free to try out the examples there in order to learn more about how to use the GraphQL APIs.
GraphQL makes it much easier to explore the interconnectedness of Stream Catalog. As we continue to populate Stream Catalog with new types of entities, the advantages of using GraphQL over the REST APIs for data discovery will continue to improve.
The future of Data Governance at Confluent
Stream Catalog is just one of three pillars among the Stream Governance offerings at Confluent. Other pillars include Stream Lineage and Stream Quality. We are continuing to invest in our data governance capabilities, so stay tuned for more exciting features across all three pillars!
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.