[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
All About the Kafka Connect Neo4j Sink Plugin
Only a little more than one month after the first release, we are happy to announce another milestone for our Kafka integration. Today, you can grab the Kafka Connect Neo4j Sink from Confluent Hub. 
Neo4j is an open source graph database that allows you to efficiently store, manage and query highly connected information. It represents data as entities (nodes) and their connections (relationships), both of which can carry arbitrary properties. You interact with Neo4j via the Cypher query language, which uses ASCII art instead of JOIN syntax to express the nifty patterns you’d usually draw on a whiteboard.
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.born < 1980 AND m.title STARTS WITH "The" RETURN p.name AS actor, collect(m.title) as movies, count(*) as total ORDER BY total DESC LIMIT 10
Neo4j provides drivers for JavaScript, Java, Python, Go and .NET out of the box and supports other languages via community drivers. You can install Neo4j on your desktop, run it via the official Docker image or deploy it to cloud providers. Neo4j comes with a fancy developer UI that renders results of your queries as network visualization or tables.
Customers deploy Neo4j Enterprise with more production features like clustering, monitoring, security to address use cases like network management, recommendation, fraud detection, investigative research and more.
Neo4j extension – Kafka sink refresher
We’ve been using the work we did for the Kafka sink – Neo4j extension and have made it available via remote connections over our binary bolt protocol. So you can stream your events from Apache Kafka® directly into Neo4j to create, update and enrich your graph structures. Then it is really up to you what you want to with the event data.
The events can come from frontend systems, API notifications, other databases or streaming systems like Apache Spark™ and Apache Flink®.
For details on the format and internals, please see our previous article or the documentation for the Neo4j sink.
You control ingestion by defining Cypher statements per topic that you want to ingest. Those are then executed for batches of events coming in.
Testing the Kafka Connect Neo4j Sink
Installing and using the connector is pretty straightforward. Just download it from Confluent Hub via the command line client or via the UI and install it into your Kafka Connect setup.
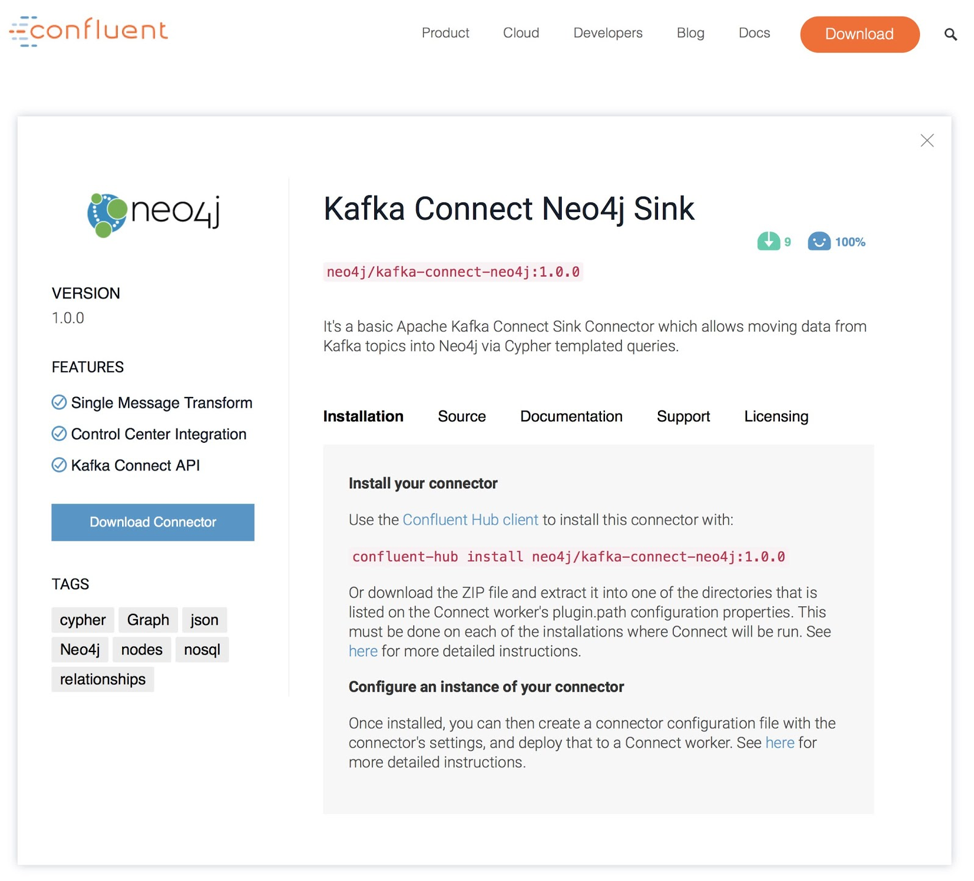
confluent-hub install neo4j/kafka-connect-neo4j:1.0.0
In terms of configuration, post the following configuration to Kafka Connect:
{
"name": "Neo4jSinkConnector",
"config": {
"topics": "my-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "",
"neo4j.encryption.enabled": false,
"neo4j.topic.cypher.": ""
"neo4j.topic.cypher.": ""
}
}
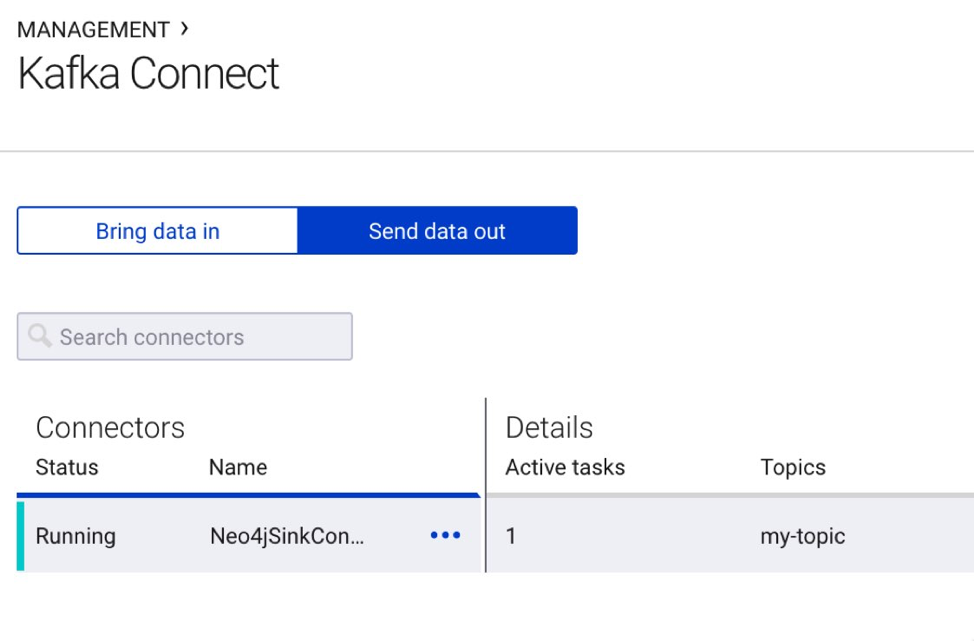
It then shows up in the Confluent management UI:
 Local testing with Docker Compose
Local testing with Docker Compose
If you just want to test it locally, you can follow the steps below. For a complete overview of the steps, please refer to this link.
Download this Docker Compose file and start the stack with the command:
docker-compose up -d
Once the stack is up and running, let’s install the Kafka Connect sink plugin by executing in the command line:
docker exec -it connect confluent-hub install --no-prompt neo4j/kafka-connect-neo4j:1.0.0
Then, let’s create the sink instance by posting configuration to the /connectors endpoint.
curl -X POST http://:8083/connectors \ -H 'Content-Type:application/json' \ -H 'Accept:application/json' \ -d @contrib.sink.avro.neo4j.json
File contrib.sink.avro.neo4j.json:
{
"name": "Neo4jSinkConnector",
"config": {
"topics": "my-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://neo4j:7687",
"neo4j.authentication.basic.username": "neo4j",
"neo4j.authentication.basic.password": "connect",
"neo4j.encryption.enabled": false,
"neo4j.topic.cypher.my-topic": "MERGE (p:Person{name: event.name, surname: event.surname, from: 'AVRO'}) MERGE (f:Family{name: event.surname}) MERGE (p)-[:BELONGS_TO]->(f)"
}
}
In particular, the line:
"neo4j.topic.cypher.my-topic": "MERGE (p:Person{name: event.name, surname: event.surname}) MERGE (f:Family{name: event.surname}) MERGE (p)-[:BELONGS_TO]->(f)"
…defines that all the data that comes from the topic my-topic will be inserted by the sink into Neo4j with the following Cypher query:
MERGE (p:Person{name: event.name, surname: event.surname})
MERGE (f:Family{name: event.surname})
MERGE (p)-[:BELONGS_TO]->(f)
Under the hood, the sink injects the event object in this way:
UNWIND {batch} AS event
MERGE (p:Person{name: event.name, surname: event.surname})
MERGE (f:Family{name: event.surname})
MERGE (p)-[:BELONGS_TO]->(f)
Where {batch} is a list of event objects, you can change the query or remove the property and add your own, but you must follow this convention:
"neo4j.topic.cypher.": ""
Once all is configured properly, you can run the Kafka event data generator to see your nodes and relationships appearing magically in your Neo4j instance, creating 100,000 test events in Apache Avro™ format:
java -jar neo4j-streams-sink-tester-1.0.jar -f AVRO -e 100000
The Kafka monitoring UI can be found at http://:9021/management/connect.
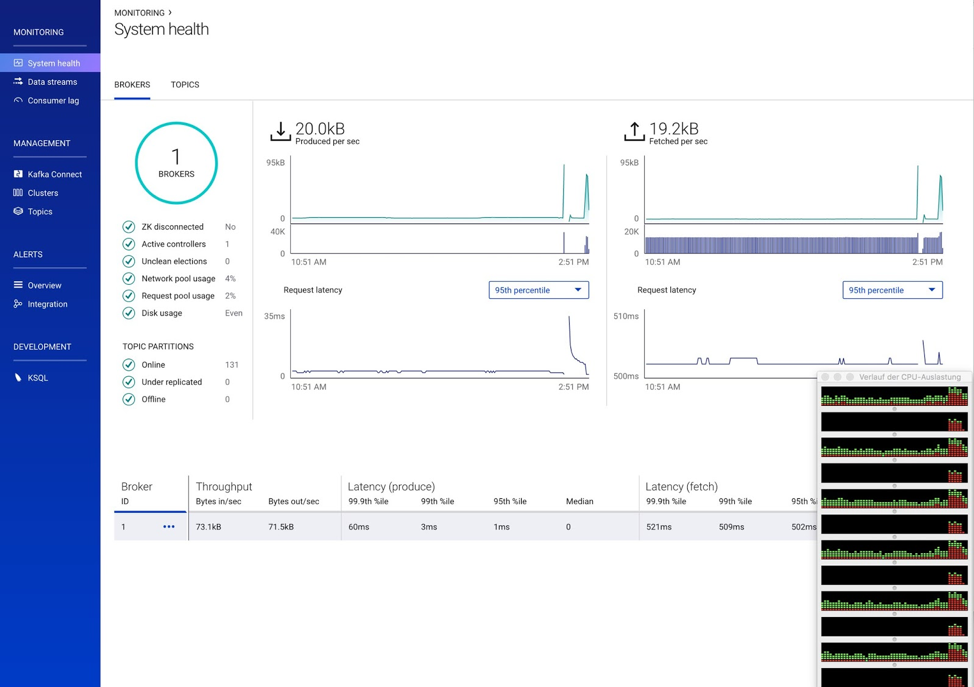
They show up properly in my topic and then are added to Neo4j via the sink. As you can see, running it all in Docker locally is a bit taxing to our CPUs. 🙂
Below, you see that the data was ingested into Neo4j. During our testing, we processed more than 2 million events at one time.
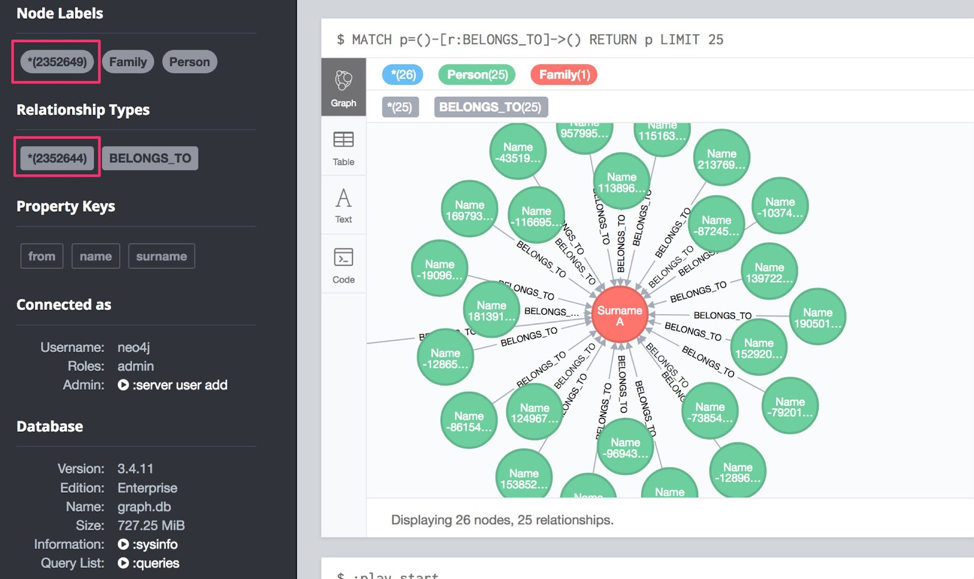
Streams procedure to receive data
The Neo4j Streams project comes with two procedures that allow producing/consuming messages directly from Cypher:
- streams.publish allows custom message streaming from Neo4j to the configured environment by using the underlying configured producer
- streams.consume allows messages to be consumed from a given topic
New streams.publish procedure
This procedure allows custom message streaming from Neo4j to the configured environment by using the underlying configured producer.
It takes two variables in input and returns nothing (as it sends its payload asynchronously to the stream):
- topic, type String: the topic to send the events to
- payload, type Object: what you want to stream
For example:
CALL streams.publish('my-topic', 'Hello World from Neo4j!')
The message retrieved from the consumer is:
{"payload": "Hello world from Neo4j!"}
You can send any kind of data in the payload: nodes, relationships, paths, lists, maps, scalar values and nested versions thereof.
In the case of nodes and/or relationships in which the topic is defined in the patterns provided by the change data capture (CDC) configuration, their properties will be filtered according to the configuration.
streams.consume procedure
This procedure allows you to consume messages from a given topic.
It takes two variables in input:
- topic, type String: where you want to consume the data
- config, type Map<String, Object>: the configuration parameters
And returns a list of collected events.
The two config params are:
- timeout, type Long: the value passed to the Kafka Consumer#poll method (the default is 1,000 milliseconds)
- from, type String: the Kafka configuration parameter auto.offset.reset
Use:
CALL streams.consume('my-topic', {}) YIELD event RETURN event
Imagine you have a producer that publishes events like this:
{"name": "Andrea", "surname": "Santurbano"}
We can create nodes for people using this procedure call:
CALL streams.consume('my-topic', {}) YIELD event
CREATE (p:Person{firstName: event.data.name, lastName: event.data.surname})
We are also working with several collaborators on a few article series on how to use our Kafka integration in practice. Stay tuned.
We would love to hear from you
It would be very helpful for us, if you could help test the Kafka Connect Neo4j Sink in real-world Kafka and Neo4j settings, and fill out our feedback survey.
If you run into any issues or have thoughts about improving our work, please raise a GitHub issue.
The existing features are also covered in the documentation. If you have suggestions on how to improve it or the getting started experience, please let us know.
If you’d like to know more, you can also download the Confluent Platform, the leading distribution of Apache Kafka, and run through the quick start.
We want to thank the folks from Confluent (Josh, Robin, Victoria, Chris, Nathan and Tim) for their feedback and support in developing and publishing the connector and this article.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.