[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
Harness Trusted, Quality Data Streams with Confluent Platform 7.1
Streaming data has become critical to the success of modern businesses. Leveraging real-time data enables companies to deliver the rich, digital experiences and data-driven backend operations that delight customers. For the many businesses that operate across a variety of on-prem data centers and cloud providers, unlocking these digital initiatives as they scale requires sharing high-quality, consistent data streams across multiple environments. However, it remains challenging to create this consistent data fabric because of data sprawl, with each source having its own schema and limited solutions for sharing and syncing schemas across hybrid and multicloud environments in real time.
With the release of Confluent Platform 7.1, we’re building on top of the innovative feature set announced in recent releases, providing several enhancements that allow companies to harness trusted, quality data across all environments with speed, scale, and stability. Confluent Platform 7.1 delivers three primary benefits to enable this vision:
- Ensure globally consistent data across hybrid environments with shared schemas that sync in real time
- Improve scale, speed, and cost-effectiveness while maintaining operational simplicity with increased DevOps automation and expanded Tiered Storage options
- Enhance reliability and global resilience with additional intelligent alerts and multi-region capabilities for containerized environments
In this blog post, we’ll explore each of these benefits in detail, taking a deeper dive into the major feature updates and enhancements. As with previous Confluent Platform releases, you can always find more details about the features in the release notes and in the video below.
Keep reading to get an overview of what’s included in Confluent Platform 7.1, or download Confluent Platform now if you’re ready to get started.
Download Confluent Platform 7.1
Confluent Platform 7.1 at a glance
Confluent Platform 7.1 comes with several major enhancements, enabling data streaming everywhere, bringing more of the cloud-native experience of Confluent Cloud to your self-managed environments, and bolstering the platform with a complete feature set to implement mission-critical use cases end-to-end. Here are some highlights.
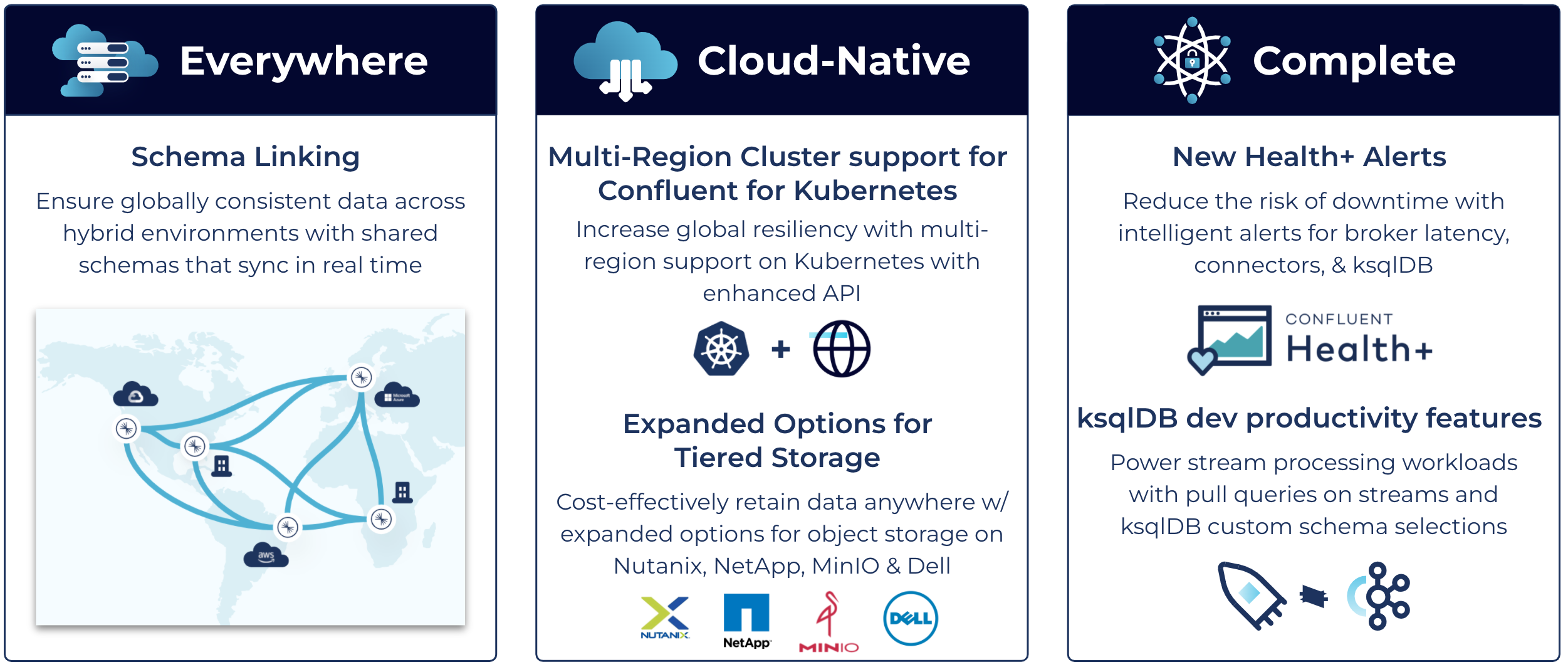
Confluent Platform 7.1 reinforces our key product pillars
Schema Linking
In Confluent Platform 7.0, we announced the general availability of Cluster Linking, which enables you to easily link clusters together to form a highly available, consistent, and real-time bridge between on-prem and cloud environments and provide teams with self-service access to data wherever it resides.
Operating connected clusters across environments introduces an increased need for globally enforced standards to maximize data quality. However, ensuring evolving schemas are always up-to-date and in sync across environments is a challenge. An open source replication tool like MirrorMaker 2 may be considered to transfer schemas, but this requires a separate component to deploy and monitor, along with complex manual operations that lack a simple interface to work directly with schemas.
This is where Schema Linking, recently introduced in Confluent Cloud, shines. Now generally available for Confluent Platform, Schema Linking provides an operationally simple means of maintaining trusted, compatible data streams across hybrid and multicloud environments by sharing consistent schemas between independent clusters that sync in real time.
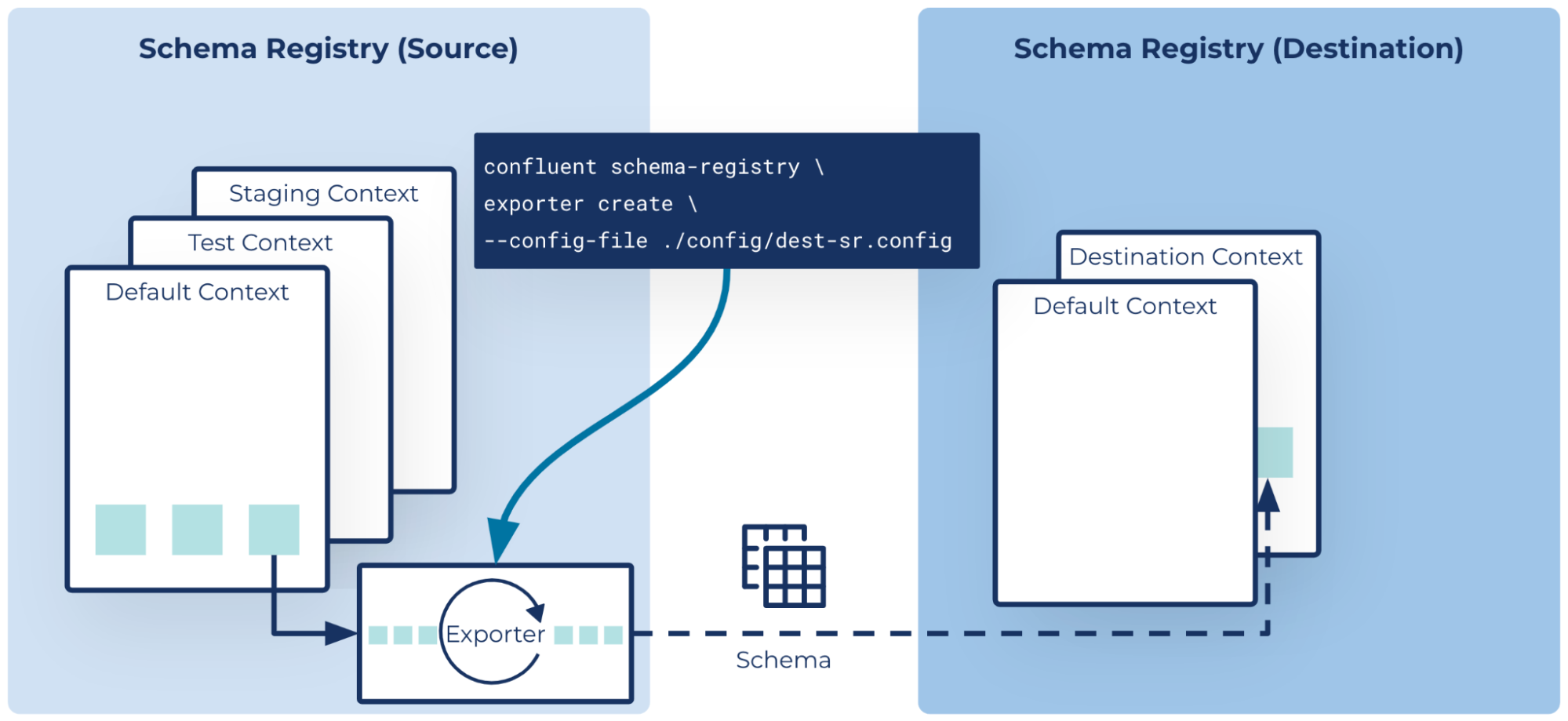
Easily sync schemas between source and destination clusters
Schema Linking introduces two new concepts which create a simple interface to interact with schemas and keep them in sync. First, schema contexts are an independent grouping of schema IDs and subject names, allowing the same schema ID in different contexts to represent completely different schemas. These help facilitate the transfer of schemas from source to destination. Second, schema exporters act as mini-connectors for schemas between different environments, making it easy to move schemas from one cluster to another.
Schema Linking supports real-time syncing of schemas for both active-active and active-passive setups—this includes common Cluster Linking use cases, such as cluster migration and real-time data sharing and replication. Leveraged alongside Cluster Linking, schemas are shared everywhere they’re needed, providing an easy means of maintaining high data integrity to ensure a consistent data fabric across the entire business.
Confluent for Kubernetes 2.3
Last year, we released Confluent for Kubernetes, which allows you to build your own private cloud Apache Kafka® service using a complete, declarative API to deploy and operate Confluent. We support enterprise Kubernetes distributions such as VMware Tanzu Kubernetes Grid (TKG), Red Hat OpenShift, and any distribution meeting the Cloud Native Computing Foundation’s (CNCF) conformance standards.

Confluent for Kubernetes supports all major enterprise Kubernetes distributions
With this latest release, we’re excited to introduce support for Multi-Region Clusters, enabling customers to build a globally resilient architecture that supports ultra-low RPO/RTO while also realizing the cloud-native benefits that come from deploying on Kubernetes. With this addition, Confluent for Kubernetes now supports the entire feature set of Confluent Platform, so customers can take full advantage of the intelligent, API-driven operations offered by Confluent for Kubernetes across all of their use cases.
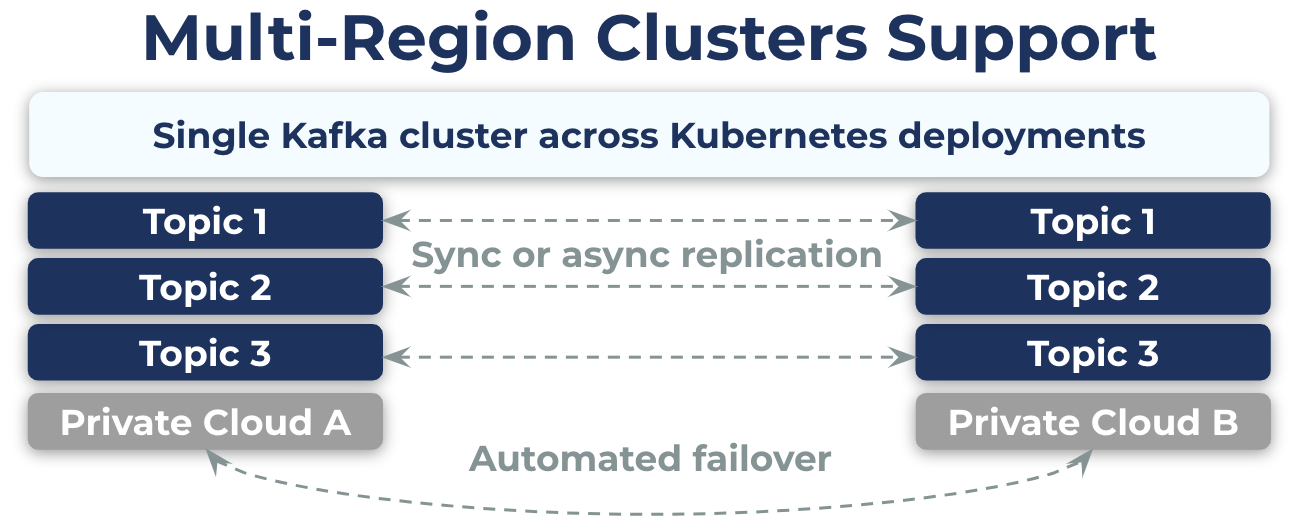
Multi-Region Clusters support across Kubernetes deployments
In addition to multi-region support, we’re enhancing the API in two ways. First, we’re now providing support to declaratively configure custom volumes attached to Confluent deployments—enabling use cases such as managing user-provided connectors that are loaded and deployed automatically. Second, complementing the release of Schema Linking, we’re also adding schema links to the list of components that can be declaratively defined and managed to simplify operations and accelerate time-to-value with self-managed Confluent clusters.
apiVersion: platform.confluent.io/v1beta1
kind: Connect
spec:
mountedVolumes:
volumes:
- name: customJars
azureFile:
secretName: azure-secret
shareName: aksshare
readOnly: true
volumeMounts:
- name: customJars
mountPath: /mnt/customJars
Provide custom connector JARs through a mounted volume
Expanded options for Tiered Storage
In Confluent Platform 6.0, we introduced Tiered Storage, which enables Kafka to recognize two layers of storage—local storage on the broker and cost-efficient object storage, thereby allowing brokers to offload older topic data to the latter to reduce the costs of self-managing Kafka.
This addressed a couple of issues with how Kafka manages storage. First, this makes cluster maintenance simpler and more efficient, since operations such as recovering from broker failures and adding or demoting a broker don’t require as much time to copy data stored locally to a new broker. Second, storing data long-term on Kafka is now a viable option since you’re not limited to expensive local storage, saving you up to 10 times in storage costs.
In Confluent Platform 7.1, we’re introducing expanded options for long-term object storage on Nutanix, NetApp, MinIO, and Dell. This allows more of our customers to take advantage of the elasticity, operational, and performance benefits of Tiered Storage, bringing Confluent Cloud’s intelligent two-tier storage engine on-prem. We’ve also put these systems through rigorous performance and quality testing while building strong relationships with each vendor to allow for seamless customer support.
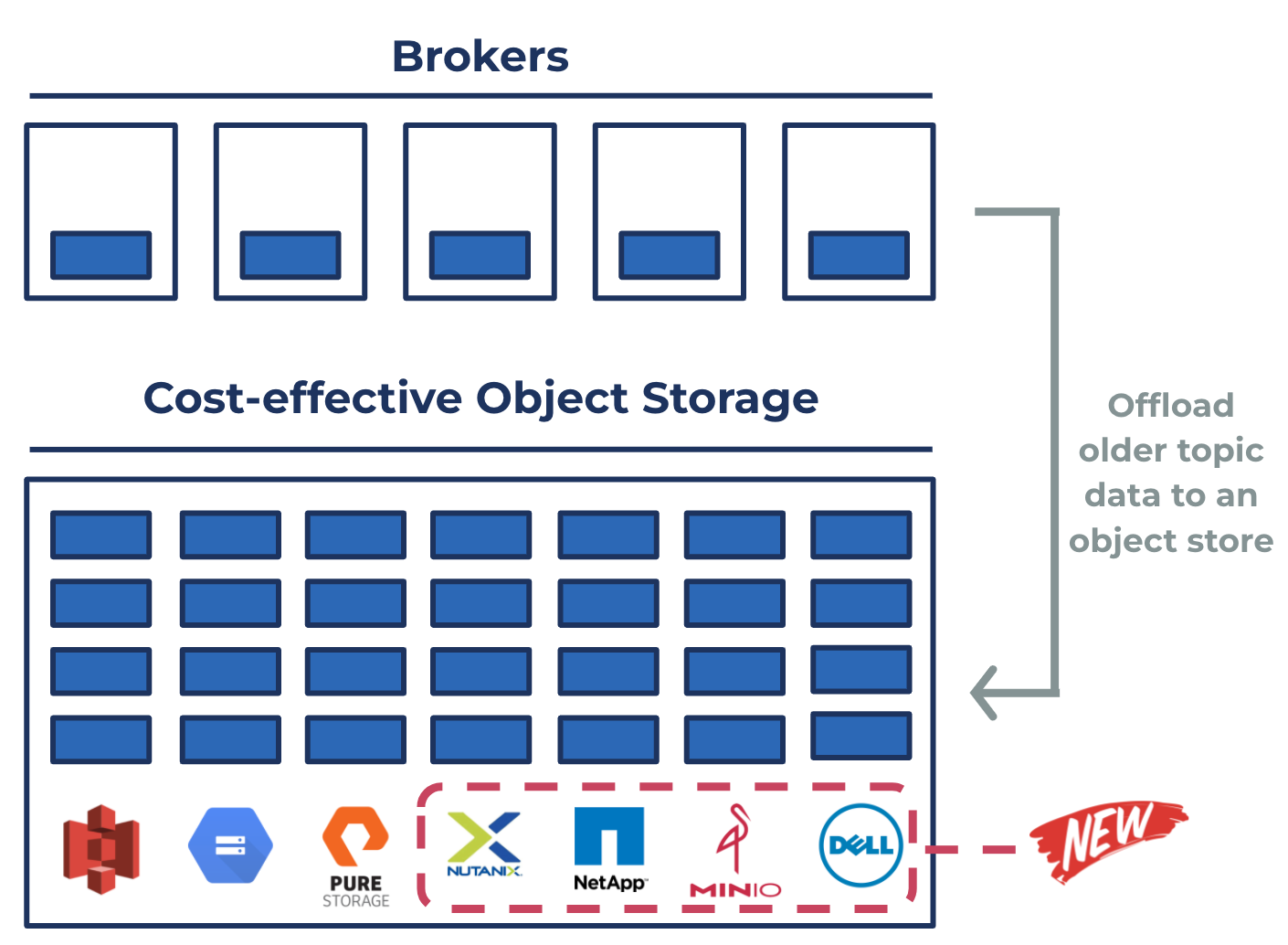
Expanded options for Tiered Storage on Nutanix, NetApp, MinIO, and Dell
Virtually unlimited storage for on-prem clusters opens up new possibilities. Here are some key scenarios enabled by Tiered Storage:
- Improved elasticity and scalability
You may want to scale and balance workloads more quickly to provide better performance for end users. Adding or removing brokers requires shifting partitions between brokers, requiring full data replication for the rebalance to complete. When using Tiered Storage, the majority of the data is offloaded to object storage, so only a small subset of the data on the broker’s local disk must be replicated, reducing the time needed to rebalance partitions, expand or shrink clusters, or replace a failed broker. - Reprocessing of historical data
Confluent is often used to build real-time data pipelines, in which data is ingested from different source systems, processed via stream processing, and then sent to downstream data systems and applications. If the stream processing logic needs to change (whether due to changing business requirements or errors) or you are building a new pipeline that needs a full data dump or snapshot, you may need to (re)process historical data. Tiered Storage allows you to do this without time-consuming operations. - Streamlined capacity planning
Platform operators often face tradeoffs between offering their developers longer data retention periods and minimizing their infrastructure costs—the longer the retention period, the more costly hardware that is required. This is no longer a tradeoff with Tiered Storage, as operators don’t have to choose between retention times and exhausting disk space or needing to unexpectedly expand disks or clusters. Developers can also request additional disk space on demand without worrying about imposing time-consuming interventions on operators.
In summary, Tiered Storage enables the storage of data in Kafka long-term without having to worry about high costs, poor scalability, and complex operations. Expanded options mean you can now achieve cloud-native scale and near-infinite storage on prem.
Additional intelligent alerts for Health+
In Confluent Platform 6.2, we introduced Health+, which offers intelligent alerting and cloud-based monitoring tools to reduce the risk of downtime, streamline troubleshooting, surface key metrics, and accelerate issue resolution. We launched with 10 total validations, including alerts for disk usage, unused topics, and idle time percentage, while continuing to build additional alerts and enhancements.
Confluent Platform 7.1 now offers additional intelligent alerts for broker latency, connectors, and ksqlDB to identify and avoid issues before they result in costly downtime by using Confluent’s library of expert-tested rules and algorithms, tuned from operating over 15,000 clusters in Confluent Cloud. Here are the benefits of each:
- Broker latency alerts (preview): Detect anomalies in broker latency to make sure you are within your expected operating SLAs
- Connector alerts: Ensure reliable integration between Kafka and common external systems by proactively monitoring the state of connectors for failures
- ksqlDB alerts: Examine queries for potential issues to maintain continuous real-time processing streams
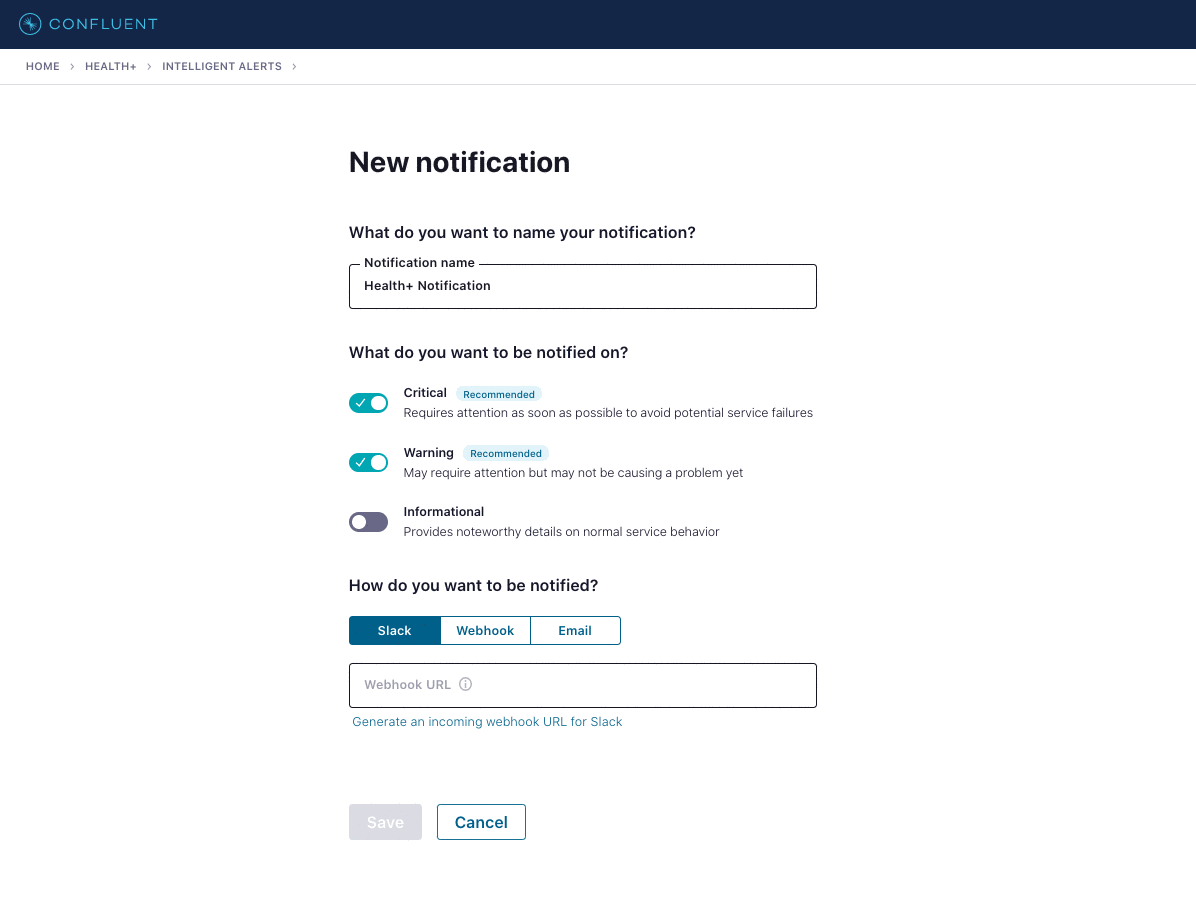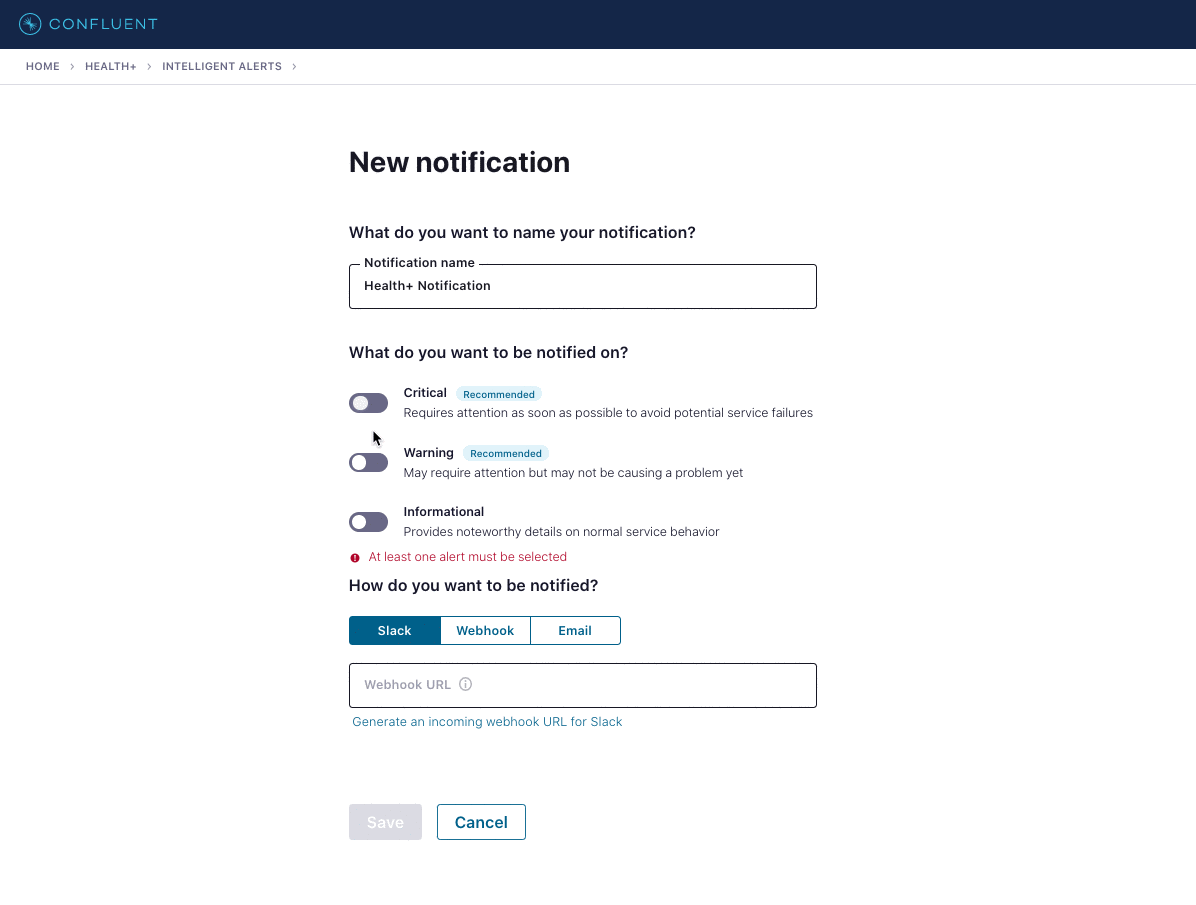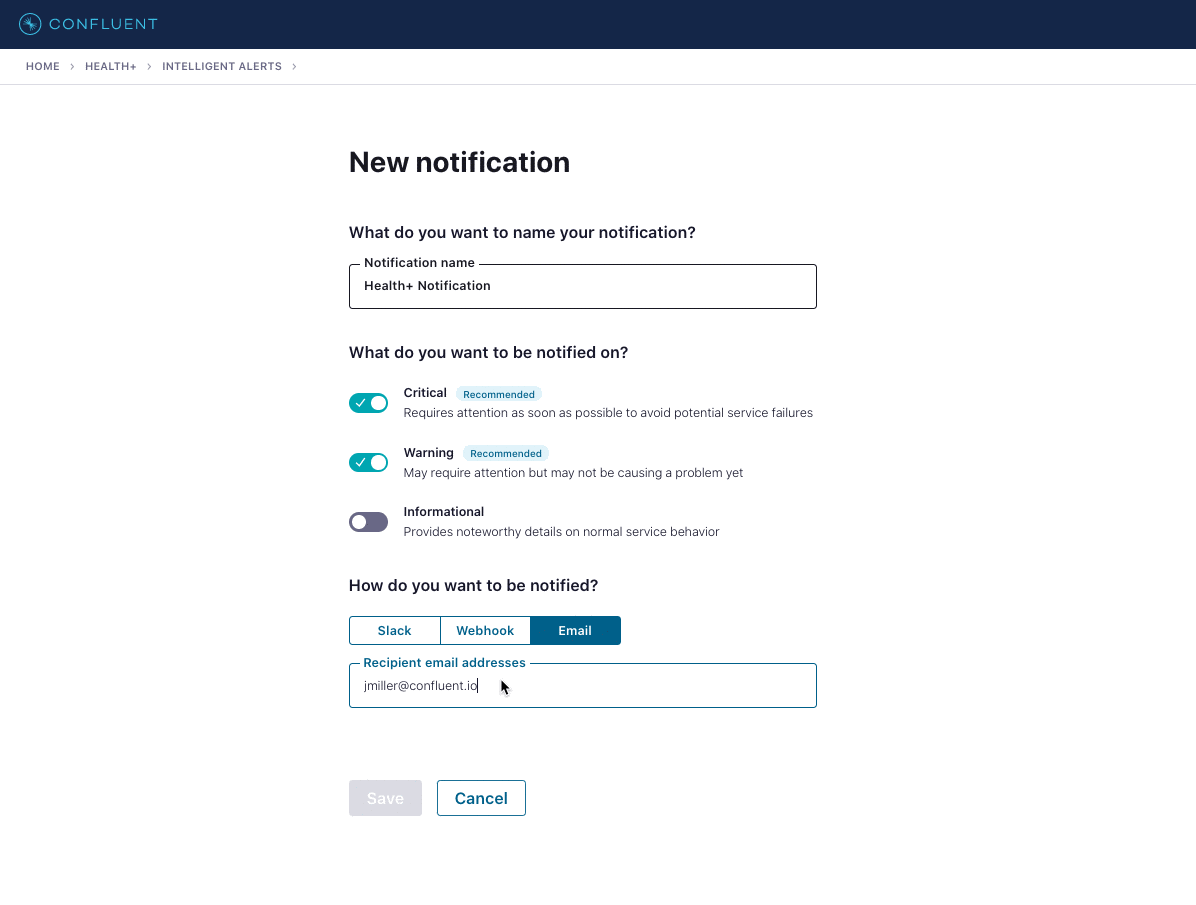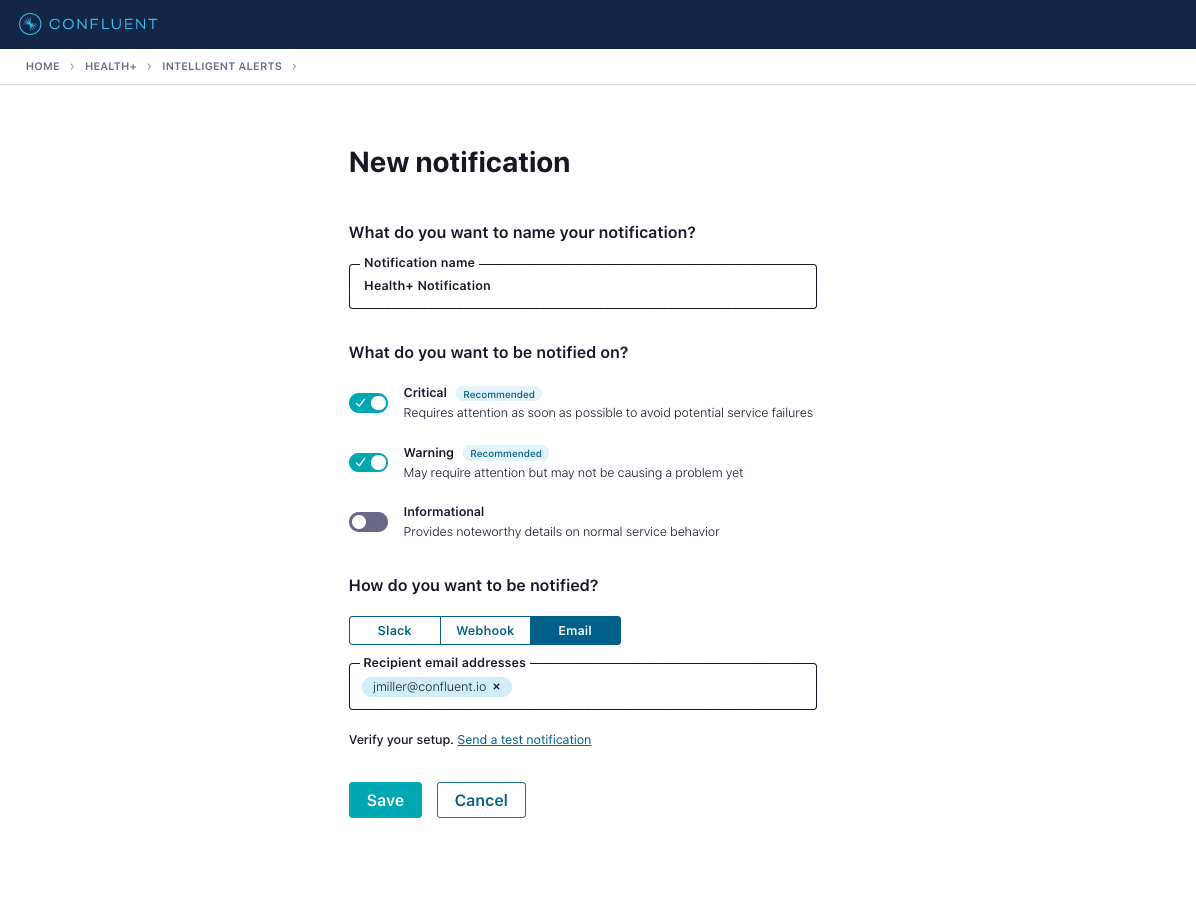
Additional intelligent alerts for broker latency, connectors, and ksqlDB
With Health+, you can easily view all of your critical metrics surfaced by these alerts in a single cloud-based dashboard and speed issue resolution with accelerated diagnosis and support from our industry-leading Confluent Support team of experts. This also significantly reduces TCO by offloading monitoring of on-prem clusters to a scalable, cloud-based solution, shrinking your monitoring infrastructure costs by up to 70%. If you are interested in Health+, you can sign up for free.
ksqlDB 0.23
Confluent Platform 7.1 also comes with ksqlDB 0.23, which includes several new enhancements that expand stream processing workloads and make it easier for developers to build real-time applications.
One of the biggest enhancements is support for pull queries over streams. A common task in setting up streaming use cases is inspecting a subset of messages within a Kafka topic for debugging purposes. In previous releases of ksqlDB, pull query functionality was only supported on tables and not streams. Because of this limitation, searching for individual messages required using a low-level consumer, adding several tedious steps for developers.

Scan the entire stream for easier debugging
In Confluent Platform 7.1, support for pull queries on streams now allows developers to more easily debug data flows. You no longer have to drop down to low-level consumers and slow down development with a lengthy debugging process, enabling you to focus on more value-added efforts. The ability to scan over a Kafka topic and apply complex filtering logic can also be used to inspect topic messages to verify that the data is correct and properly structured and formatted.
In addition, ksqlDB now supports custom schema selection, which offers more options and control when using Schema Registry. By default, ksqlDB automatically generates schemas for streams and tables based on the latest registered schemas for the input topic. Now, you can have ksqlDB use a specific schema ID instead when you create your new stream or table rather than the latest registered schema. This also allows you to specify a particular output schema for persistent queries when creating materialized views.
CREATE STREAM pageviews
WITH (
KAFKA_TOPIC='pageviews-avro-topic',
VALUE_FORMAT='AVRO'
);
Previously, only the default registered schema was used
CREATE STREAM pageviews
WITH (
KAFKA_TOPIC='pageviews-avro-topic',
VALUE_FORMAT='AVRO'
VALUE_SCHEMA_ID=1
);
Now, use a specific schema by ID instead of the latest registered schema
The new functionality covers use cases where ksqlDB’s existing schema generation and topic-name-based inference are not ideal. For example, custom schema selection allows ksqlDB to adopt a different version of the schema that’s expected by downstream services rather than the default schema registered with the topic. Also, when writing to a data source, the physical schema inferred by the schema ID is used to serialize data instead of ksqlDB’s logical schema, preventing the creation of duplicates and reducing compatibility errors.
With Confluent Platform 7.1, ksqlDB also includes a number of additional enhancements that streamline real-time stream processing application and pipeline development:
- Support for reading metadata stored in Kafka record headers
- Access to record partition and offset data
- Optimization for push queries for the common scenario in which many similar push queries are being run concurrently
Support for Apache Kafka 3.1
Following the standard for every Confluent release, Confluent Platform 7.1 is built on the most recent version of Apache Kafka, in this case, version 3.1. This version allows out-of-the-box configuration by any Kafka users to connect to popular identity provider services, such as Okta or Auth0 (KIP-768) and provides consistency with the way client metrics are presented by Kafka for monitoring (KIP-773).
For more details about Apache Kafka 3.1, please read the blog post by David Jacot.
Want to learn more?
Check out Danica Fine’s video and podcast for an overview of what’s new in Confluent Platform 7.1, and download Confluent Platform 7.1 today to get started with the complete platform for data in motion, built by the original creators of Apache Kafka.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.