[Webinar] Von Notfallmaßnahmen zu Null-Verlust-Resilienz | Jetzt registrieren
Introducing Confluent Platform 5.4
I am pleased to announce the release of Confluent Platform 5.4. Like any new release of Confluent Platform, it’s packed with features. To make them easier to digest, I want to break them down into three categories.
First, features like Role-Based Access Control, Structured Audit Logs, Multi-Region Clusters, and broker-level Schema Validation are all prerequisites for a production-ready deployment of an event streaming platform. And when running efficiently at scale, you’ll need Confluent Control Center to help you manage and monitor all these feature and more. You’ll also need preview access to innovations like Tiered Storage. Finally, when you’re actually building applications on Confluent Platform, you’ll need developer productivity tools like KSQL pull queries and the KSQL REST API, and the many new features in Apache Kafka® 2.4.
Download Confluent Platform 5.4
Building an event-driven architecture with Apache Kafka allows developers to transition from traditional silos and monolithic applications to more modern microservices and event streaming applications that fundamentally increase their agility and accelerate their time to market.
However, in addition to Kafka, larger enterprises need certain foundational architectural attributes around security, resilience, and compliance that are considered production-stage prerequisites. They also need additional tools and features that would allow them to run Kafka efficiently at very large scale.
As always, the release notes have the full story, but this blog post has a summary of the highest of the high points. Read on for more.
Production-stage prerequisites
The larger the enterprise, and the longer it has been around, the more complex its IT environment. That complexity can breed risk and fragility, as layers of legacy systems add a growing attack surface able to be exploited by malicious actors, impacted by poor quality controls, or altogether taken down by both internal errors or external forces. Any of these occurrences can halt operations, damage revenue streams, and tarnish an organization’s reputation indefinitely and irreparably in front of end customers and business partners.
Nobody wants that. Which is why Confluent Platform 5.4 has strengthened its enterprise-grade security support in the form of Role-Based Access Control (RBAC) and Structured Audit Logs.
Role-Based Access Control (RBAC)
Back in July, we announced the preview for RBAC as part of the Confluent Platform 5.3 release. After gathering feedback and learning from everyone who tried it out, we are now pleased to announce the availability of RBAC in Confluent Platform 5.4. You can now make use of this feature in production environments with Confluent’s full support.
RBAC offers a centralized security implementation for enabling access to resources across the entire Confluent Platform with just the right level of granularity. You can control permissions you grant to users and groups to specific platform resources, starting at the cluster level and moving all the way down to individual topics, consumers groups, or even individual connectors. You do this by assigning users or groups to roles. This gets you out of the game of managing the individual permissions of a huge number of principals—a real problem for large enterprise deployments.
RBAC delivers comprehensive authorization enforced via all user interfaces (Confluent Control Center UI, CLI, and APIs), and across all Confluent Platform components (Control Center, Schema Registry, REST Proxy, MQTT Proxy, Kafka Connect, and KSQL). Given the distributed architecture not only of Apache Kafka but also of other platform components like Connect and KSQL, having a single framework to centrally manage and enforce security authorizations across all the components is, in a word, essential for managing security at scale.
Structured Audit Logs
Another new security-related feature in 5.4 are Structured Audit Logs. Now, of course everything in Kafka is a log, but Kafka doesn’t log what Kafka does to Kafka—only what you produce to topics. But what about creating topics, changing permissions, and modifying access control lists (ACLs)? Those are all very important operations that can impact the security and overall functioning of the cluster. It would be good to keep a record of them, which is exactly what Structured Audit Logs do in Confluent Platform.
Structured Audit Logs enable authorization logs to be captured in a set of dedicated Kafka topics, either on a local or a remote cluster, including:
- Audit logs of low-volume, management-related activities, such as creating or deleting ACLs or topics (enabled by default)
- Audit logs of high-volume activities, such as inter-broker communication or produce/consume events (can be enabled as needed)
With all those events safely in topics, you can then use Kafka-native tools, like the Kafka Streams API or KSQL, to process and analyze them. You can also offload them to external systems for analysis, like Splunk or Amazon S3, using Confluent-supplied sink connectors.
To provide industry-backed standardization, Structured Audit Logs use the CloudEvents specification to define the format of the logs. CloudEvents is a vendor-neutral specification that defines the format of event data and is rapidly becoming the industry standard for describing event data. We are happy to be the first vendor in the event streaming space to support CloudEvents, and we expect it to gain significant traction going forward.
Multi-Region Clusters
Back in September, we announced the preview release of Confluent Platform 5.4, which included support for Multi-Region Clusters. With the general availability of Confluent Platform 5.4, Multi-Region Clusters can now be used for production environments.
Historically, running one cluster across datacenters—a so-called “stretch cluster”—involved significant tradeoffs, to the point where some operators actually recommended not using this topology at all. Now, Confluent Platform 5.4 gives you the ability to replicate topics across datacenters asynchronously, so the data gets across the high-latency link to the other datacenter without making your producer wait on that replication to happen for its produce operation to be considered successful. Combined with automated client failover, this gives you the ability to run a stretch cluster without the worst of the tradeoffs you’ve seen in the past.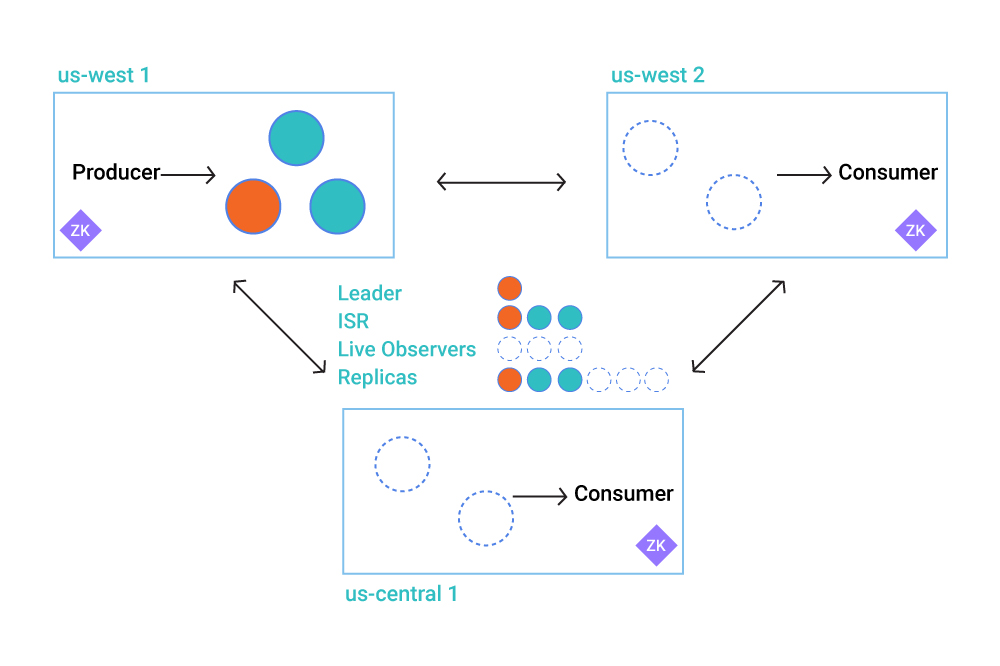 This feature delivers four big benefits that completely change the game for multi-site deployments and disaster recovery (DR) operations:
This feature delivers four big benefits that completely change the game for multi-site deployments and disaster recovery (DR) operations:
- By enabling asynchronous replication through the use of Observers and Replica Placement, you can replicate across slower and higher latency links without sacrificing write throughput and latency. This gives you more durability and more availability without significant cost to application performance.
- By leveraging the Follower Fetching (KIP-392) feature in Kafka 2.4 to allow consumers to read directly from Observers, Multi-Region Clusters eliminate unnecessary cross-WAN traffic, which drastically reduces bandwidth costs and increases throughput on reads.
- By leveraging Kafka’s internal replication, Multi-Region Clusters significantly streamline DR operations. Kafka administrators no longer have to coordinate with multiple client teams to handle failover or change DNS, and things like monitoring and security are centralized around a single cluster.
- Thanks to the automated client failover capabilities, you should be able to make meaningful improvements to recovery time objectives (RTOs). No longer must you spend precious failover time (or automation investment) on offset translations, switching DNS, or restarting clients.
Running a single stretch cluster across multiple regions has long been a desired architecture historically fraught with certain operational complexities. It was really only viable in a few scenarios because of compromises in performance, cost, and operational complexity. Multi-Region Clusters in Confluent Platform 5.4 expand those scenarios significantly, such that stretch clusters are no longer a risky choice.
Schema Validation
Confluent Platform has long included the Confluent Schema Registry, a component that helps teams collaborate around schema change and ensures at the client level that transitions from one schema version to the next will not break a consuming application. However, Schema Registry requires that everyone be a good citizen. If a producer writes to your cluster without validating messages against the registry, it can write any number of invalid messages to a topic, breaking the limits of the consumer code’s exception handling capability. And of course all of your consumer code is completely hardened against invalid inputs and will handle all of these invalid messages gracefully, but what about the many other teams writing applications against your Confluent cluster? Clearly, we must do better.
We now have the option to enable Schema Validation at the topic level. Configured in this way, Schema Validation will ensure that every single message produced to a particular topic is validated for key and value schema compliance with the corresponding policy in the Schema Registry—regardless of whether the producing and consuming clients bother to check. Any messages that are found to be invalid are dropped from the batch, and the broker sends an error indication back to the consumer.
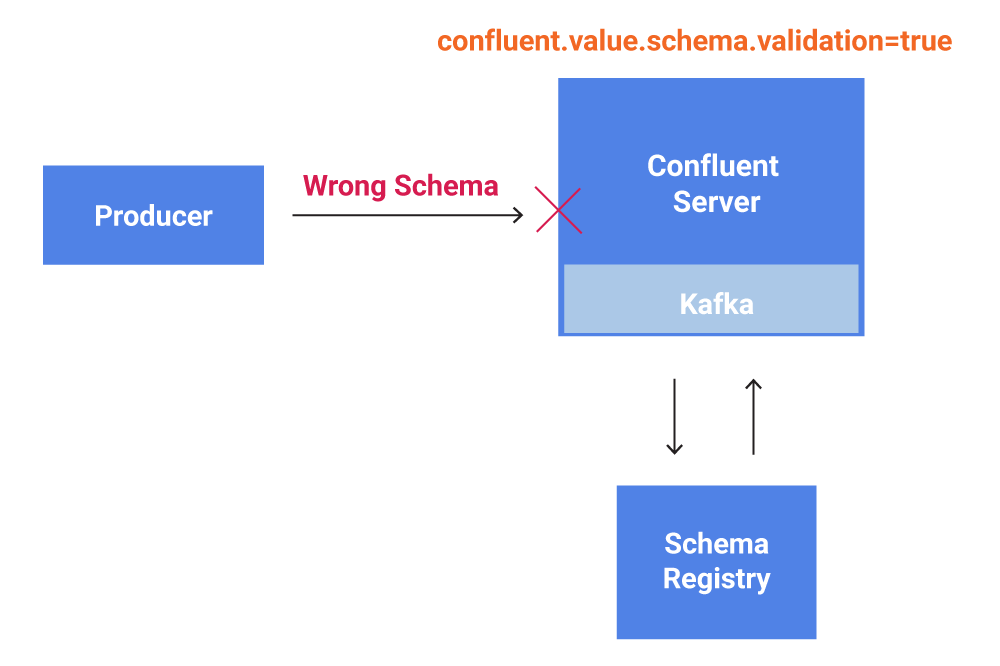
With Schema Validation, you now have much greater control over the quality of the data being written to the system. Policies that require client-level schema validation are still highly advisable, but broker-level validation is the last and best defense against malicious or negligent applications.
Efficient operations at scale
Once an enterprise has laid the technology foundation for stable, long-lasting operations, the next step is to seek more efficient operations that will allow the event streaming infrastructure to scale with as little pain as possible.
Control Center provides management for Confluent Platform 5.4 features
The introduction of new capabilities like RBAC, Multi-Region Clusters, and Schema Validation requires new interfaces to manage them. We are ensuring that Control Center remains your go-to GUI for managing and monitoring your Confluent Platform cluster by adding purpose-built support for every new feature we ship.
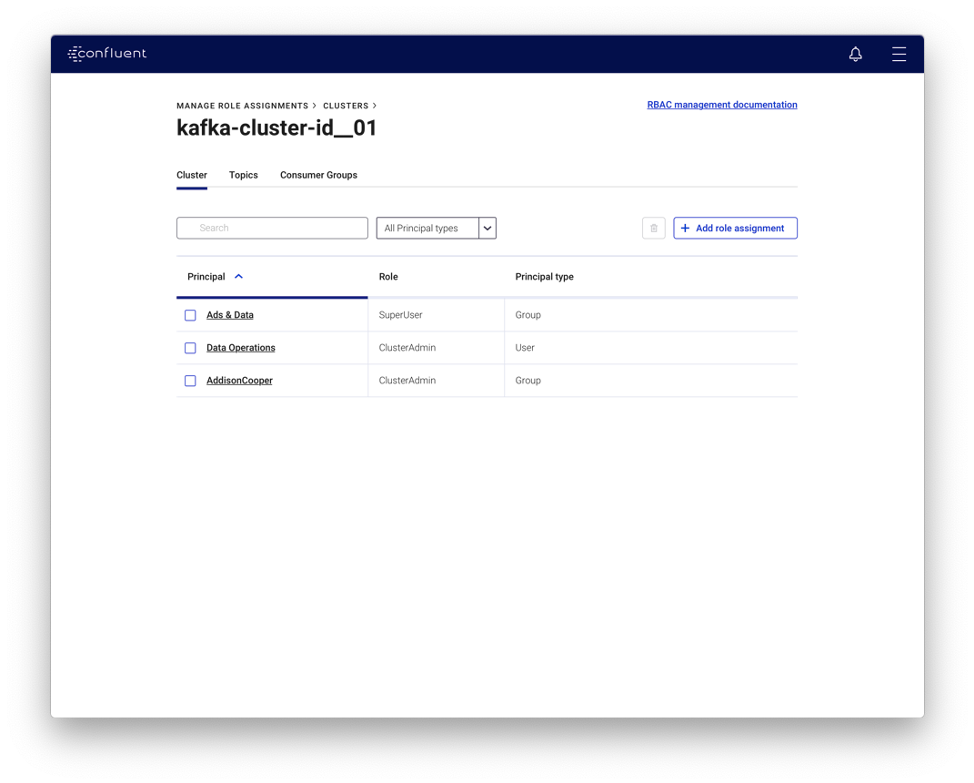
- RBAC: Control Center now provides a new login page for simpler, secure authentication. Once inside, Control Center allows users to view their own permissions, as well as to manage other users’ role bindings when they have the permissions to do so. This will greatly simplify your management of the entire organization’s security policies.
- Multi-Region Clusters: Control Center is now aware of Observers (the secret to asynchronous replication), which can be tracked as part of the replica placement section in each topic view.
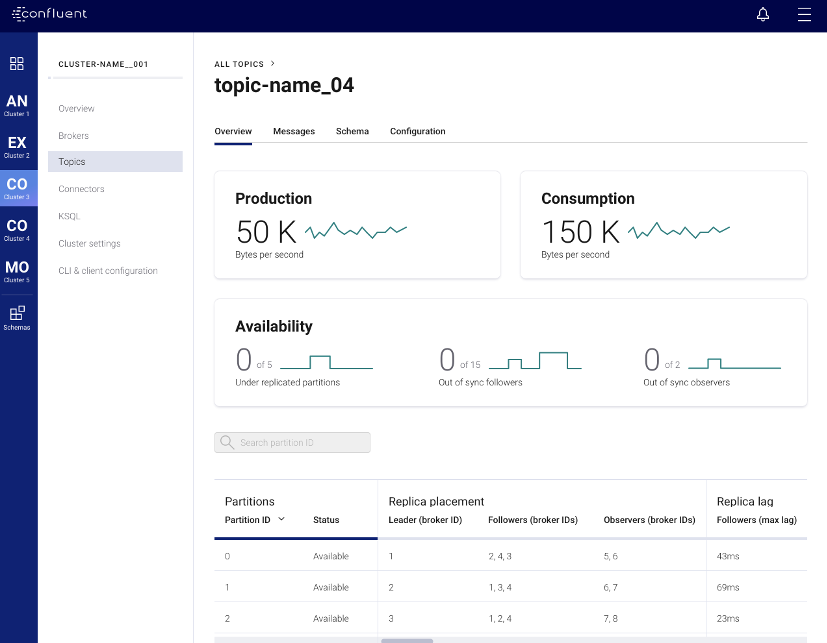
- Schema Validation: you can enable Schema Validation at the topic level when creating or editing topics within Control Center.
Confluent Replicator integrates with Control Center for visibility and monitoring
Another widely successful feature of Confluent Platform is Confluent Replicator, which allows per-topic replication across datacenters. Confluent Platform 5.4 integrates Replicator with Control Center, so you can now monitor their replication tasks directly from the GUI, just like you would monitor connectors, allowing you to track key metrics such as throughput and lag.
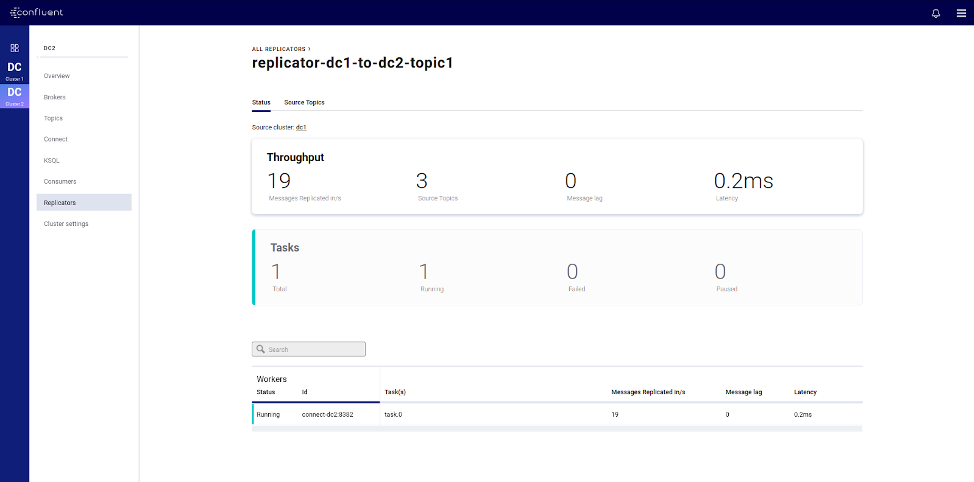
New aggregate views streamline monitoring for Kafka clusters
As a continuation of the redesign work that Control Center underwent starting with Confluent Platform 5.3, we have added a couple of overview pages that streamlines the way Kafka operators view and understand their Kafka environment.
- Cluster overview: when you sign into Control Center, click on a given Kafka cluster. You will now see an overview page, which shows the status of the cluster’s brokers, replicas, partitions, topics, Connect clusters, KSQL clusters, and more.
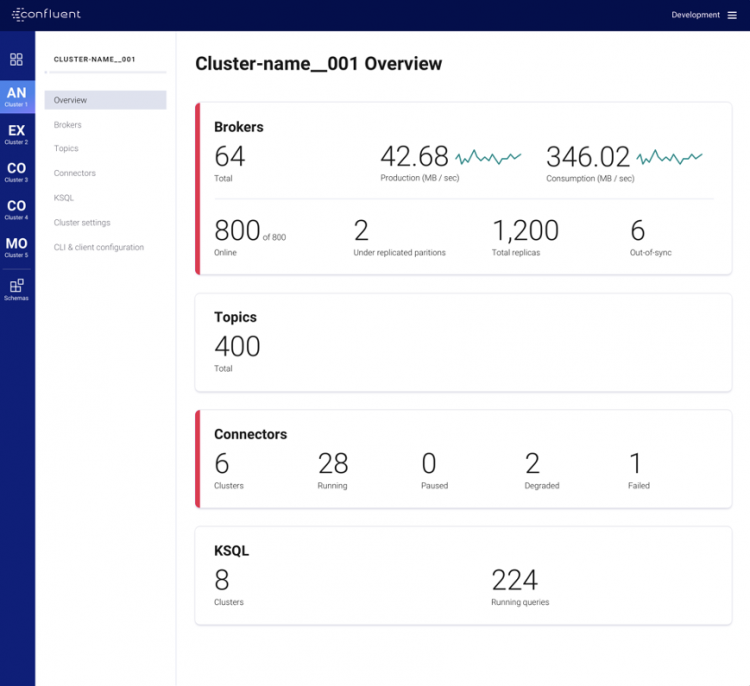
- Metrics dashboard: in previous versions of Control Center, metrics pages were scattered hither and yon depending on their particular operational context, like topic production or consumption. This new view aggregates all Kafka cluster metrics into a single page, which will help you more quickly correlate issues across various operations and metrics. Nobody wants troubleshooting to be harder, least of all us, and we hope this helps.
Tiered Storage (preview)
Some of the most successful (and to me, exciting) Confluent deployments are adopting the database inside out architectural paradigm. This is an incredibly successful model, but it encourages you to set very large retention periods on your topics. This is fantastic architecturally, but might be a little pricey as your system grows and time goes on. Tiered Storage is the obvious solution to this problem. Here’s what it can do for you:
- Infinite retention: when you need to retain very large amounts of data for long periods of time—perhaps for regulatory compliance, for backup purposes and the ability to replay data in the future, or because you’ve made Kafka your system of record as you arguably ought to—Tiered Storage lets you use low-cost cloud object storage for older data. This effectively enables infinite retention at the lowest reasonably achievable cost.
- Platform elasticity and faster data balancing: using Tiered Storage means you can scale compute without having to scale storage, and vice versa. When scaling compute, rebalancing of data becomes easier and faster, because new nodes simply point to data in the storage layer without having to move any of it from one node to another. It’s similar for scaling storage when retention or throughput requirements go up. This delivers a fundamentally higher level of elasticity for the platform.
As with any preview feature, Tiered Storage is not yet supported for production environments, which means we might make changes to APIs and underlying data formats before we reach general availability. Still: check it out now.
Unrestricted developer productivity
Apache Kafka 2.4
Following the standard for every release, Confluent Platform 5.4 is built on the most recent version of Kafka, which in this case is version 2.4. Kafka 2.4 is a feature-rich release of which there is too much to explain here, so let me sum up:
- KIP-392: Allow consumers to fetch from closest replica – Before Apache Kafka 2.4, all reads and writes happened on the leader. Now, consumers can fetch from replicas. This is an important feature that can eliminate a lot of cross-datacenter traffic, can reduce the risk of overloading the leader, and generally pushes Kafka in the direction of being more cloud native.
- KIP-455: Create an Administrative API for Replica Reassignment – Reassigning partitions is necessary to rebalance load over the brokers more evenly. Before 2.4, users initiated replica reassignment by writing directly to Apache ZooKeeper™. This KIP replaces the existing ZooKeeper-based API with an AdminClient API that supports incremental replica reassignments and cancellation.
- KIP-480: Sticky Partitioner – Prior to 2.4, when a producer wrote a message with no partition and no key, partitions were selected in a round-robin fashion, which could result in smaller batches that could lead to higher latency. KIP-480 implements a new partitioner that, whenever no partition or key is present, chooses a sticky partition until the batch is full. This greatly improves latency for topics with many partitions.
For more details about Kafka 2.4, please read the blog by Manikumar Reddy. If you prefer video to the written word, I made a video for you that’s embedded in that blog post. Sheep are present. Don’t miss it.
New KSQL features now available in preview
On November 20th, Confluent announced the release of ksqlDB, an event streaming database that seeks to unify the multiple systems involved in stream processing into a single, easy-to-use solution for building event streaming applications. ksqlDB aims to bring the approachable feel of relational databases to the world of stream processing, making it easier for developers to build the event streaming applications that are increasingly required to compete and succeed in the modern era. ksqlDB is an in-place evolution of KSQL, adding two new features (for now):
- Pull queries: pull queries complement push queries, which were previously available in KSQL. Whereas push queries allow applications to subscribe to continuously updating query results as new events occur, the new pull queries allow applications to look up a particular value from a continuously updated table. To a first-order approximation, a pull query looks just like a SELECT on a table, like you’d do in any relational database.
- Embedded connectors: rather than relying on a separate Connect cluster for getting data in and out of Kafka when integrating with external systems, you can now run Connect directly inside ksqlDB without spinning up any Connect-specific infrastructure. This means you can now run Confluent’s wide range of prebuilt connectors on ksqlDB’s servers—and you can also configure them using its lightweight SQL syntax.
For Confluent Platform 5.4, these two new features are being released in preview as part of KSQL.
Interested in more?
Watch the video summary for a quick recap of what’s new in Confluent Platform 5.4, shot in front of the South Platte River, and download Confluent Platform 5.4 to get started with a complete event streaming platform built by the original creators of Apache Kafka.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.