[Webinar] From Fire Drills to Zero-Loss Resilience | Register Now
Getting Started with Database Modernization
For many companies, the journey to the cloud started as a way to take advantage of the cost savings, speed, and scale of cloud computing. You may have already started moving some or all of your workloads from various data sources such as on-prem databases to the cloud in hopes of opening new ways to extract more value from your data.
In a previous blog post, we discussed the importance of database modernization and real-time data integration across different clouds to the cloud database of your choice. We also discussed how, across various industries, Confluent reduces the complexity and expense associated with in-house database modernization efforts.
As you can see, the future trajectory of the cloud database market is promising. Gartner predicts that by 2023, 75% of all databases will be on a cloud platform, and for 5+ consecutive years since 2017, Gartner has reported double-digit growth in the DBMS market.
As you may have experienced, knowing you want to migrate or modernize your data to set it in motion is half the battle. However, getting started is where things get, well, interesting. So before we dive into the X’s and O’s of modernizing your database, let’s make sure we have a similar understanding of what challenges companies face when self-managing their databases vs. how a cloud database aims to solve those challenges.
Self-Managed Database vs. Cloud Database
Self-managed database
- Rigid architecture that makes it hard to integrate with other systems
- Expensive in both upfront and ongoing maintenance costs
- Slower to scale to meet evolving demands
Cloud database
- Lower TCO by decoupling storage from compute and leveraging consumption-based pricing
- Increased overall flexibility and business agility
- Worry-free operations with built-in auto-scaling and maintenance cycles
Hopefully this illustrates the urgency behind why many companies are pursuing database modernization in droves to power real-time innovation and applications, and why we caution against going at it alone – especially if you don’t have to.
Now we’ll walk you through the steps you need to take to get started on your database modernization journey, which comes in three phases: Connect, Optimize, and Modernize. We’ll examine each step below in greater detail.
Connect
Connecting your existing data systems to the cloud is much easier with the help of our managed source connectors. Kafka Connect is an API native to Kafka that lets Confluent source events from other data systems such as relational databases into Kafka topics through source connectors.
Events are then taken from topics via sink connectors and sent to other data systems such as Azure Cosmos DB. Along with our partners, we maintain a growing list of 130+ vetted, fully supported Confluent connectors to help mitigate the operational risks of running OSS connectors in production.
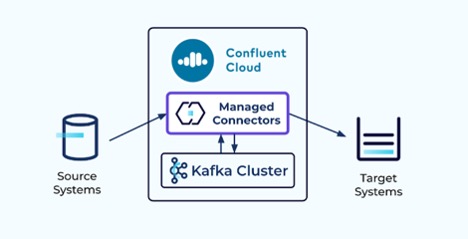
Optimize
Through ksqlDB, Confluent built an abstraction layer to the Apache Kafka Streams API, letting you create data-in-motion apps, but with SQL. Typically, if you were to leverage Streams without Confluent, you could build real-time apps, but you’d need to use Java or Scala. However, depending on the level of flexibility you require, Confluent offers a single line of code to help your team get started faster. Along with simplicity, ksqlDB is highly available, fault-tolerant and supports aggregations, joins, windowed-based queries, order handling, and even exactly-once semantics.
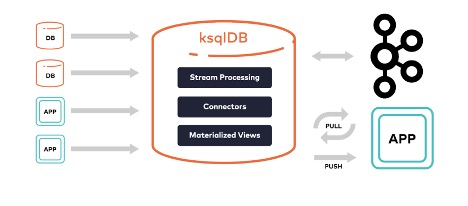
Modernize
For the final phase, our sink connectors move events from Confluent into the modern, cloud-based data system of your choice (e.g., Azure Synapse or Azure Cosmos DB). Also, we support single message transformation, which allows you to customize your data as it egresses your cluster. For example, you can take single aggregate topic and sink it to multiple systems with a single message transformation.
Confluent can be described as a ‘central nervous system’ for all your systems and applications because it allows for the free and secure flow of all parts of your business through a single platform to power real-time apps and analytics. As a result, you can eliminate the cumbersome web of point-to-point connections that plague legacy architectures and instead leverage a simple, fast, resilient, and secure data plane.
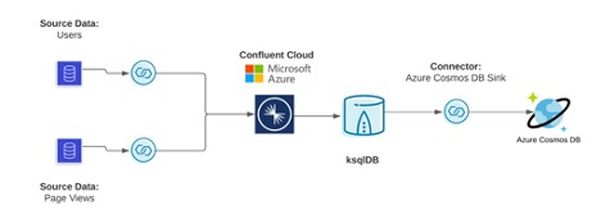
Recently named Microsoft’s Commercial Marketplace Partner of the Year, Confluent helps companies modernize their databases through Azure. We accelerate and simplify the cloud modernization process, reducing the costs of syncing on-prem and cloud deployments. Also, as companies are expected to “do more with less,” our fully managed, cloud-native, and complete data streaming platform dramatically reduces development & operational costs, burdens, and risks. Ultimately, Confluent Cloud is 10x better than managing Kafka in-house and can help companies reduce TCO by ~60%.
With Confluent, companies can connect their systems and applications via a single platform that allows data to flow uninhibited across all parts of the business – this powers innovation and real-time applications.
Ready to learn more? Join Jacob Bogie, Solutions Architect for our webinar, ‘How to Modernize Your Data Infrastructure with Confluent Cloud and Azure’ on August 18th at 10:00am PT.
During the webinar you’ll learn:
- How Confluent Cloud makes the database modernization process much easier and cost-effective for your team
- Modern and real-time data architectures.
- Best practices for creating a persistent data bridge to the cloud.
- How to get started with Confluent Cloud
We look forward to seeing you there!
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.


Thunai Automates Customer Support with AI Agents and Data Streaming
Learn how Thunai uses real-time data streaming to power agentic AI, achieving 70–80% L1 support deflection and cutting resolution time from hours to minutes.